0. 简述
现在的AI研究大部分都在专注于提升AI的推理能力,这里我们微调了一个更小的1B实验模型 MicroThinker-1B-Preview。
这样在小的GPU硬件(RTX 4090, 24GB)环境下,更容易实现,
MicroThinker-1B-Preview 的微调模型基于 huihui-ai/Llama-3.2-1B-Instruct-abliterated
微调数据集来自 PowerInfer/QWQ-LONGCOT-500K 和 PowerInfer/LONGCOT-Refine-500K
微调框架使用 modelscope/ms-swift
下面是微调过程:
1. 创建环境
|
1 2 3 4 5 6 7 8 9 10 |
mkdir MicroThinker-1B-Preview cd MicroThinker-1B-Preview conda create -yn ms-swift python=3.11 conda activate ms-swift git clone https://github.com/modelscope/ms-swift.git cd ms-swift pip install -e . cd .. |
如果在windows 下,可能需要重新安装 torch
|
1 2 |
pip uninstall torch torchvision torchaudio pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124 |
2. 下载模型和数据集
|
1 2 3 |
huggingface-cli download huihui-ai/Llama-3.2-1B-Instruct-abliterated --local-dir ./huihui-ai/Llama-3.2-1B-Instruct-abliterated huggingface-cli download --repo-type dataset PowerInfer/QWQ-LONGCOT-500K --local-dir ./data/QWQ-LONGCOT-500K huggingface-cli download --repo-type dataset PowerInfer/LONGCOT-Refine-500K --local-dir ./data/LONGCOT-Refine-500K |
3. 第一阶段微调
这里–num_train_epochs 1表示训练了1个epoch,
qwq_500k.jsonl#20000 表示只用了前20000条记录
|
1 2 |
set CUDA_VISIBLE_DEVICES=0 swift sft --model huihui-ai/Llama-3.2-1B-Instruct-abliterated --model_type llama3_2 --train_type lora --dataset "data/qwq_500k.jsonl#20000" --torch_dtype bfloat16 --num_train_epochs 1 --per_device_train_batch_size 1 --per_device_eval_batch_size 1 --learning_rate 1e-4 --lora_rank 8 --lora_alpha 32 --target_modules all-linear --gradient_accumulation_steps 16 --eval_steps 50 --save_steps 50 --save_total_limit 2 --logging_steps 5 --max_length 16384 --output_dir output/Llama-3.2-1B-Instruct-abliterated/lora/sft --system "You are a helpful assistant. You should think step-by-step." --warmup_ratio 0.05 --dataloader_num_workers 4 --model_author "huihui-ai" --model_name "MicroThinker" |
下面两张图显示微调结果,其他图可以在 images 下找到
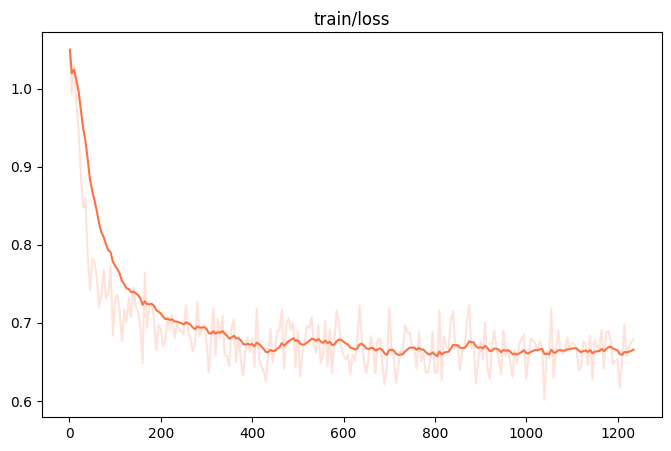
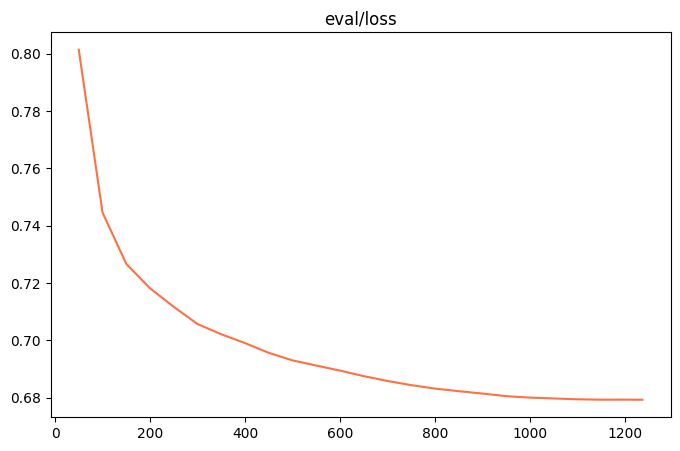
4. 保存第一阶段微调后的模型
|
1 2 |
set CUDA_VISIBLE_DEVICES=0 swift infer --model huihui-ai/Llama-3.2-1B-Instruct-abliterated --adapters output/Llama-3.2-1B-Instruct-abliterated/lora/sft/v3-20250102-153619/checkpoint-1237 --merge_lora true |
应该会产生新的模型目录 checkpoint-1237-merged
把这个目录复制或是移动到 huihui 目录下
5. 第二阶段微调
这里–num_train_epochs 1表示训练了1个epoch,
qwq_500k.jsonl#20000 表示只用了前20000条记录,
refine_from_qwen2_5.jsonl#20000 表示也只用了前20000条记录。
|
1 2 |
set CUDA_VISIBLE_DEVICES=0 swift sft --model huihui-ai/checkpoint-1237-merged --model_type llama3_2 --train_type lora --dataset "data/QWQ-LONGCOT-500K/qwq_500k.jsonl#20000" "data/LONGCOT-Refine-500K/refine_from_qwen2_5.jsonl#20000" --torch_dtype bfloat16 --num_train_epochs 1 --per_device_train_batch_size 1 --per_device_eval_batch_size 1 --learning_rate 1e-4 --lora_rank 8 --lora_alpha 32 --target_modules all-linear --gradient_accumulation_steps 16 --eval_steps 50 --save_steps 50 --save_total_limit 2 --logging_steps 5 --max_length 16384 --output_dir output/checkpoint-1237-merged --system "You are a helpful assistant. You should think step-by-step." --warmup_ratio 0.05 --dataloader_num_workers 4 --model_author "huihui-ai" --model_name "MicroThinker" |
6. 推理
找到微调的输出目录 output/Llama-3.2-1B-Instruct-abliterated/lora/sft 下面的目录
|
1 2 |
set CUDA_VISIBLE_DEVICES=0 swift infer --model huihui-ai/checkpoint-1237-merged --adapters output/checkpoint-1237-merged/v4-20250101-235059/checkpoint-800 --stream true --infer_backend pt --max_new_tokens 2048 |
7. 保存最后的模型
假设你选择的lora 的目录是 checkpoint-1237,下面的命令执行完毕后,合并后的模型应在 checkpoint-1237-merged 目录里面。
|
1 2 |
set CUDA_VISIBLE_DEVICES=0 swift infer --model huihui-ai/checkpoint-1237-merged --adapters output/checkpoint-1237-merged/v4-20250101-235059/checkpoint-1237 --merge_lora true |
8. 对保存后的模型进行推理
切换到 checkpoint-1237-merged目录的上一层目录,下使用下面的命令进行测试
|
1 |
swift infer --model checkpoint-1237-merged --stream true --infer_backend pt --max_new_tokens 2048 |
测试的例子;
|
1 |
How many 'r' characters are there in the word "strawberry"? |
9. 已经完成的模型
下面链接是已经微调完成的模型:
MicroThinker – a huihui-ai Collection
ollama 也可以直接测试:
|
1 |
ollama run huihui_ai/microthinker |