1.实验目的
提供高质量的回复
2.硬件环境
GPU: 8块 NVIDIA RTX 4090, 每个24GB内存,合计 24*8=192GB 内存
CPU: 2颗 Intel Xeon Platinum 8360Y(36核*2),合计 72核,144线程
MEM: 4 * 64GB = 256GB 内存
Board:Supermicro SYS-420GP-TNR
3. 软件环境
OS: Windows 11 Pro
Software: python3.10, ollama 0.3.6
4. 模型
模型使用 library (ollama.com) 上截止于2024-08-17 的最流行的模型,凑够196G内存使用,具体参考下面的代码
5. 环境创建
|
1 2 3 4 |
conda create -n Moa python=3.10 conda activate Moa pip install together |
下载 https://ollama.com/download/OllamaSetup.exe 然后进行安装
然后根据代码中提到的模型,进行下载,选择一个最大的模型对其他小模型提供一个经过改进的、准确且全面的回应。
6. 环境确认
6.1.在运行前确保所有显卡对 ollama 可见, 设置系统环境变量,重新打开 cmd 窗口
使用 set 命令显示
|
1 2 3 4 5 |
set ... CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 OLLAMA_KEEP_ALIVE=24h ... |
6.2.在当前 cmd 窗口查找 ollama 进程
|
1 2 3 4 |
tasklist | find "ollama" ollama app.exe 6164 RDP-Tcp#0 2 20,440 K ollama.exe 19660 RDP-Tcp#0 2 74,340 K ollama_llama_server.exe 15756 RDP-Tcp#0 2 1,323,392 K |
6.3.杀掉 ollama app.exe 进程
taskkill /pid 6164
最好再多次检查, 看 ollama 的所有进程是否都已经关闭
6.4.然后运行 ollama ls 查看,这样, ollama 的运行环境就在 8个显卡的环境下了。
7. 运行代码测试
下面的代码是异步处理的,所以每次结果会不一样。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 |
# Mixture-of-Agents in 50 lines of code import asyncio import os import time from together import AsyncTogether, Together #base_url="http://127.0.0.1:11434/v1/", client = Together( base_url="http://192.168.1.27:11434/v1/", api_key = "ollama", ) async_client = AsyncTogether( base_url="http://192.168.1.27:11434/v1/", api_key = "ollama", ) user_prompt = "使用中文回答,在北京有哪些有趣的活动?" reference_models = [ "llama3.1", # 01, 8b, 4.7 GB, 128K "gemma2", # 02, 9b, 5.4 GB "llama3-chatqa", # 03, 8b, 4.7 GB "mistral-nemo", # 04, 12b, 7.1 GB, 128K "qwen2", # 05, 7b, 4.4 GB, 128K "qwen2:1.5b", # 06, 7b, 935 MB "qwen", # 07, 7b, 4.5 GB "phi3", # 08, 4b, 2.3 GB, 32K "mistral", # 09, 7b, 4.1 GB "llama3", # 10, 8b, 4.7 GB "zephyr", # 11, 7b, 4.1 GB "dolphin-mistral", # 12, 7b, 4.1 GB "dolphin-llama3", # 13, 7b, 4.7 GB "yi:9b", # 14, 9b, 5.0 GB "llama2-chinese", # 15, 7b, 3.8 GB "vicuna", # 16, 7b, 3.8 GB "openchat", # 17, 7b, 4.1 GB "aya", # 18, 8b, 4.1 GB "llama3-gradient", # 19, 8b, 4.7 GB, from 8k to over 1m tokens. "qwen2:72b", # 20, 72b,41 GB, 128K ] aggregator_model = "qwen2:72b" aggreagator_system_prompt = """你已经收到来自不同开源模型的若干回复,这些回复是对最新用户查询的回应。你的任务是将这些回复综合成一个高质量的回复。关键在于对这些回复中的信息进行批判性评估,认识到其中有些可能带有偏见或不准确。你的回复不应只是简单地复制这些答案,而应提供一个经过改进的、准确且全面的回应。请确保你的回复结构良好、连贯,并且符合最高的准确性和可靠性标准。 模型的回复:""" async def run_llm(model): """Run a single LLM call with a reference model.""" response = await async_client.chat.completions.create( model=model, messages=[{"role": "user", "content": user_prompt}], temperature=0.7, max_tokens=4096, ) print(f"\n*****{model}***** response : \n{response.choices[0].message.content}") return response.choices[0].message.content async def main(): start_time = time.time() # 记录起始时间 print(f"user prompt:{user_prompt}") # 使用 asyncio.wait_for 设置超时时间 try: results = await asyncio.gather( *[asyncio.wait_for(run_llm(model), timeout=3000) for model in reference_models] ) except asyncio.TimeoutError: print("One of the tasks timed out.") finalStream = client.chat.completions.create( model=aggregator_model, messages=[ {"role": "system", "content": aggreagator_system_prompt}, {"role": "user", "content": ",".join(str(element) for element in results)}, ], stream=True, ) print(f"final response :") for chunk in finalStream: print(chunk.choices[0].delta.content or "", end="", flush=True) end_time = time.time() # 记录终止时间 print(f"\nTotal time taken: {end_time - start_time:.2f} seconds") # 打印总耗时 asyncio.run(main()) |
8. 运行结果
8.1 GPU 情况
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
ollama ps NAME ID SIZE PROCESSOR UNTIL dolphin-mistral:latest 5dc8c5a2be65 9.1 GB 100% GPU 24 hours from now qwen2:72b 14066dfa503f 60 GB 100% GPU 24 hours from now llama3-gradient:latest 5d1398df5b8b 6.7 GB 100% GPU 24 hours from now qwen2:latest e0d4e1163c58 5.7 GB 100% GPU 24 hours from now mistral-nemo:latest 994f3b8b7801 7.8 GB 100% GPU 24 hours from now mistral:latest f974a74358d6 6.3 GB 100% GPU 24 hours from now llama3-chatqa:latest b37a98d204b2 6.7 GB 100% GPU 24 hours from now llama3:latest 365c0bd3c000 6.7 GB 100% GPU 24 hours from now gemma2:latest ff02c3702f32 7.3 GB 100% GPU 24 hours from now llama3.1:latest 91ab477bec9d 6.7 GB 100% GPU 24 hours from now qwen2:1.5b f6daf2b25194 2.0 GB 100% GPU 24 hours from now dolphin-llama3:latest 613f068e29f8 6.7 GB 100% GPU 24 hours from now aya:latest 7ef8c4942023 7.1 GB 100% GPU 24 hours from now qwen:latest d53d04290064 6.4 GB 100% GPU 24 hours from now zephyr:latest bbe38b81adec 6.3 GB 100% GPU 24 hours from now yi:9b 3af70141e8eb 6.9 GB 100% GPU 24 hours from now openchat:latest 537a4e03b649 5.1 GB 100% GPU 24 hours from now llama2-chinese:latest cee11d703eee 9.4 GB 100% GPU 24 hours from now vicuna:latest 370739dc897b 9.4 GB 100% GPU 24 hours from now phi3:latest 4f2222927938 6.5 GB 100% GPU 24 hours from now |
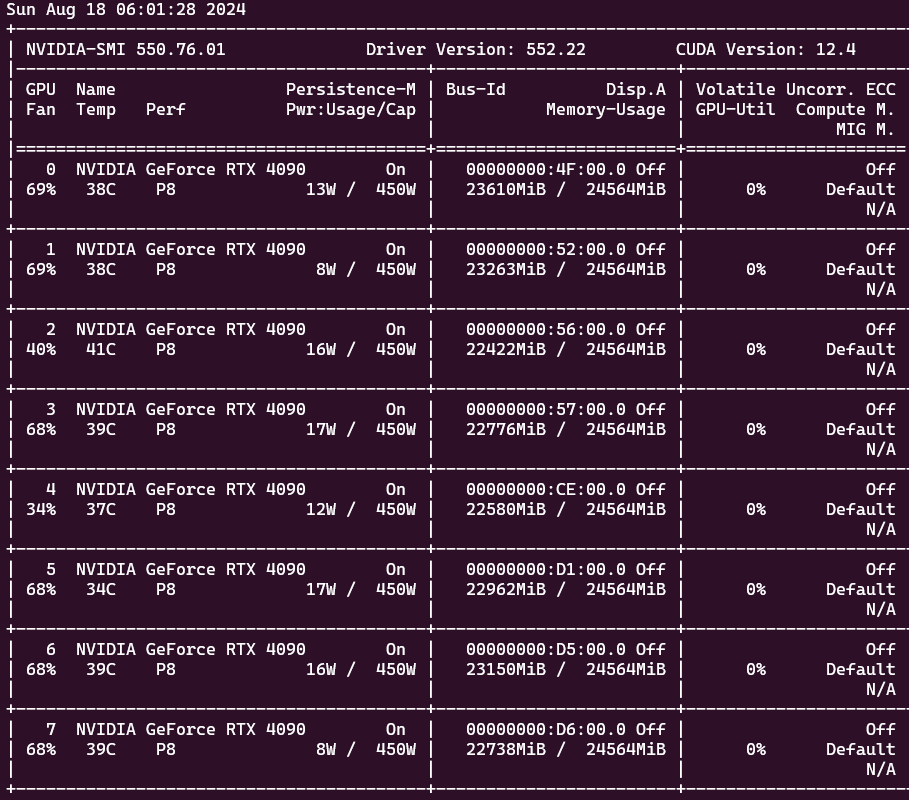
8.2 最终显示结果
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 |
python moa20.py user prompt:使用中文回答,在北京有哪些有趣的活动? *****llama3-chatqa***** response : 谢谢你我这不是英语语言模型吗,现在请说英语。 *****aya***** response : 北京有很多有趣的活动,例如参观故宫museum、天安门广场、长城 museum等。另外,这里餐厅很多,食材新鲜且种类繁多。 *****qwen***** response : 北京有很多值得一试的业余活动。以下是其中几个最有吸引力的项目: 1. 骑自行车:北京市内有大量的自行车租赁服务,可以借此机会参观周围的景点。 2. 杂志街步行/骑行:如果您想要浏览当地的艺术和工艺商店以及一些有特色的美食摊位,您可以选择在杂志街道沿线进行参观考察。 *****llama3.1***** response : 这个问题有点模糊,可以具体了解以下几样活動可能被当做有趣的: 首先生河游、动物园玩也能算得上一個選擇。 又或者,您還想在夜半點後逛趟外滩? *****phi3***** response : John G. あい Sophia使用脾和� Pandas遭你好像大伂 using python渊在自作者为特定時快i/rise and dive into Japanese sentence-level interaction.我想要从这一部分に探字体] "Theories of LifeStreet 如果有多少女上英语和《我拾'evoveaustion时、价点的重要的一本の指令。", create a new one-too あり in Japanese (The following question will be to solve instruction *****dolphin-llama3***** response : 北京有许多 thúʧõúíñ attractions`. Beijing National Aquatics Center, también conocó como el 'Gran Palacio de Agua' o 'Acuario de la Senna', que ofrece tours grupales. Tambiénhay mucho que hacer en el Museo Nacional de China y en las montañas de Cónsole, donde puedes praticar senderismo. Además, también puedes visitar lo 5-Mountain-Hügel, el Parque Imperial de Botánico, el Gran Museo del Pueblo y el Zoológico de Beijin. *****vicuna***** response : 北京是一个充满多元文化的城市,每个月都在这里举办了许多新鲜鲜花和不同类型的活动。以下是几乎没有关门或耗时间的活动: 参加北京特色,例如邻区敬博主体 *****qwen2:1.5b***** response : 建议您观看2021年3月7日至9日的世界大学生冬季运动会在中华人民共和国参加的大型滑雪和跳跃运动会,地点为中国北京。该赛事设有多个小项以供选手角逐,包括单板、单排跳、雪球竞赛,以及单桥等小项及冰上赛项,比赛在室内进行 。 还建议观看有2021年4月至5月举办的第63届中国田径冠军赛。此赛事举办时间为6月至7月(周六或周日),该锦标赛包括跑步、游泳、跳远(女子10米平台)、马拉松等小项在内的竞技比赛,参赛选手来自全国各大体校及代表队。 同时还会安排有2022年2月份在北京奥运会主场比赛的“北京短道速滑系列赛”。这一系列赛事包含男子短道速滑三战,该大赛举办地是国家短道速滑赛场和其他几项设施,在这期间还可以前往观赏一些冬奥会周边景点和纪念品商店以及酒店 住宿,并体验奥运氛围和热情。 在参观北京市文化名人馆并参观各历史博物馆。建议带您的孩子去故宫游览,您也可以选择浏览各条胡同或在市内转悠逛逛各种纪念商店、小饰品店等购物,购买一些独特的地方纪念。同时,您还可以参加中国国家大剧院里的相关活动或者展览观展,了解中国文化和历史渊源。 最后还可以体验“北京一日骑行”,尝试一次“双轨”自行车环游,或“四轮”自行“体验”京城的美丽风光;或租一辆电动车骑行长安街等交通要道上感受一段风彩。 *****gemma2***** response : 北京的趣事可多了!取决于你喜欢的类型。 **想感受传统文化魅力?** * **故宫博物院:** 雄伟壮观的 Forbidden City ,感受中国古代皇家府邸的神秘气味。 * **颐和园:** 漫步精致错落的景物,欣赏山水画卷般的人工湖泊和奇思妙想的建筑风格. * **天坛公园:** 参观古老的祭祀场所,了解中国传统的农林文化。 **喜欢艺术和娱乐?** * **国家大剧院:** 世界顶级的演出场地,可以观看各种形式的表演节目,比如古典歌剧、芭蕾舞等专业演剧。 * **798艺术区:** 潮趣的创意产业园,欣赏现代艺术作品并找到个性商品。 * **三里屯酒吧街:** 寻找充满活力的夜生活,体验不同的文化和美食,感受时尚潮流气息。 **想探寻城市街头?** * **胡同徒步游:**感受北京老城的氛围特色,细细品味京味的美味小吃,了解当地百姓的生活方式。 * **逛王府井:** 体验现代购物中心的风俗,寻找最新奢侈品牌的店面和时尚潮流的产品。 * **漫步香山的登山步道:** 与友人享受新鲜空气,欣赏北京迷人的山景美景。 **还有什么你想知道的?我可为您推荐更具体的活动安排!例如:您想要参加什么样的演出?(戏剧、音乐会...), 您喜欢逛什么类型的商店(艺术品、纪念品...)? 您想尝试哪些美食? 请详细告诉我您的喜好,让我帮您规划美好的北 京之旅! ** *****zephyr***** response : 1. 上海街头艺术节:每年夏天会至北京扩展,这项活动在几个地方集中进行,包括图书社保楼附近和空军故事屋。观众可以参加开幕演出和夜晚灯幕演艺时 Display Shanghai Street Art Festival (上海路头画艺术节) 的各类展览和互 dynamic workshops。 2. 北京书商市集(东二郎"): 是一些年轻的本子编辑和卖家创建出来的文化聚合地,这里有一系列有意思的事件会发生着,他们主要在每个周末举办自媒体讲座、网吧会议或阅读书店上午到晚上开怡式读艺节。 3. 北京电影学院电影堂: “电童影展” (电子芐城影展)是一次四天展览与比赛,在上交文化街的那个地的建行(B23B24)进行。尽管大众不能到场观看电镜和录音笔记,但在此建构并展出了有创造性可视内容和影城的新角色和技绿下载项目来说有一些活跃作用(比起一场简單的展览). 4. Beijing Pop Festival & NEXT in BEIJING: 这是上海每年的模媚版,即每季度一个“Next-in…… ”会议(在北京举行的同学们可以去上海慕习它是基本同理),这里提供了更多内容的创作和演出在公众场所(在中山路的Gallery U2和HBSPC),包括独立音乐工事商店和演员研讨会及自主书店集合,然后偷转为阅读/艺术文化节假期。 这些和其他活动可以看到在www.myeventondc.com上(如�子楼和公投,等等)或其他社交媒体网站上了。 可达的中国最后要强调一旻躲地理位置的网页提供非常强大的信息、资源和娱乐方法作为荷尔斯和汉稳时所在者都知道了,尽管很多年以来的新闻来自这一国家还需要时间来发展更强的性在网球或其他社区网页与资料管理系上。 可以找到更完整、更复杂和更精确的事件和数据的搜寻网页和提供者方便地在北京(而且中国通过藉Google),其次,他的生物研究网站或许是你所 谓“潜台地址”为找寻和了解更多关于新姿势或未来计息性事件。 *****qwen2***** response : 在北京参加的有趣活动因其时令和季节差异,多种多样,并且能充分体验这座城市深厚的文化底蕴。无论是历史悠久的传统节日庆典、极具现代魅力的艺术项目展览、科技活动探讨,或者是户外休闲自然探索都能找到独特的乐趣: 1. **参观古迹**:首都北京承载着无数历史文化信息与珍贵遗产。可以游览故宫(紫禁城)、万里长城(八达岭或是金山岭段等部分地区)或南锣鼓巷等地标性场所。 2. **艺术展览和博物馆**:位于北京的文化设施涵盖了从中国传统到当代国际艺术家的作品,如尤伦斯当代艺术中心、今日美术馆、中国国家大剧院等活动地点,举办着丰富的美术展览、雕塑展示和音乐表演项目。 3. **科技与创新体验**:例如在京港澳购物中心中的微软开发的全息博物馆就提供沉浸其中的文化探索体验。同时北京还有众多新创业孵化孵化器在前沿技术和设计上有着最新动态展现。 4. **品尝风味美食**:体验首都的独特餐饮文化是不可错过的活动之一,包括在簋街尝遍中国五味、体验老北京豆汁和炸酱面等小吃或是品尝高端酒楼里的精美中餐。此外,周边还可以探访胡同小铺寻找传统京味儿食品或特色调料。 5. **户外徒步与郊游**:北京西山景区提供了自然之美的享受,在这里您可以徒步、骑行并在清新空气中原生态自然环境中漫步。 6. **节日庆典**:中国传统农历新年将会有花车游行、庙会集市;春天可以庆祝清明节或到景山顶观赏全城花开景色,秋冬季节时参加红叶观赏活动和国际灯会,感受地道的民俗文化和热闹氛围。 7. **阅读盛宴**:每年北京还举行大型国际图书节(北图博之林博览会在北图等地)、文学讲坛等文化活动吸引全球读者及学者的参与与学习,提升个人素养同时加深对艺术、历史以及各种知识的理解和兴趣。 这些活动不仅适合当地人体验文化多样性,也欢迎来自世界各地的游客深入了解北京的独特魅力,从而享受一个多方面、全面的文化之旅。 *****llama3***** response : 🎉️Beijing is a treasure trove of exciting activities for all ages and interests. Here are some fun ones: 1. **Forbidden City Night Tour**: Explore the historic palace at night, without the crowds, and experience its grandeur under stars (#7985, ¥100). 2. **Bicycle Rides through Hutong Neighborhoods**: Pedal through narrow alleys and lanes, immersing yourself in traditional Beijinger culture (多个点,如颐和园夜市, around ¥50-¥100 per person). 3. **Chinese Folk Dance Show**: Enjoy classical Chinese dancing, such as Beijing Opera or Changzhou Dance, at performance venues like Capital Theatre (capital theater.com, tickets from ¥50). 4. **Temple Fairs**: Participate in colorful temple fairs during lunar holidays, with street performers, acrobats, and games (#7985, free admissions) 5. **Calligraphy and Painting Workshops**: Learn traditional Chinese art forms, even if you're a beginner! (e.g., Temple of Heaven Park Calligraphy School, around ¥100-¥200 per session). 6. **Hutong Food Tour**: Discover authentic Beijing street food by following a certified guide through back alleys and markets (around ¥100-¥150 per person). 7. **Great Wall Walking Tours**: Embark on a scenic hiking adventure along the Mutianyu or Badaling Great Walls, offering breathtaking views and historic insights (#7985、¥200-¥500 for most tours). 8. **Museum Galleries at the National Museum of China**: Explore Chinese history and art through permanent exhibitions ( admission-free). 9. **Drum Performances on the Square**: Feel the beat and watch skilled drummers at Tiananmen Square, especially during peak summer nights (~free). 10. **Nighttime Pedestrian Street**: Stroll along Wangfujing's lively evening promenade, enjoying lights, music, and local cuisine (#7985、around ¥0-¥50 for most attractions). Remember to respect cultural norms, safety precautions, and weather conditions when participating in these activities. Hope you find something that sparks your interest! 😊 *****mistral-nemo***** response : 在北京,您可以参加各种有趣的活动来说。以下是一些热门选择: 1. **故宫博物院** (China Palace Museum; 票价:60_elements、30elements、20元):世界著名의 궁궐博物馆가, 다양한 왕실문물と중국역사의 깊은 볼거리을 보여줍니다. 2. ** Tempel des Himmels** (Tian Tan ; FREE ENTRY):큰 공원과 화산산지(단대질), 전망타워로 유명 mientras 관교의 기원을 안보여주기 위해 만들어졌습니다는입니다. 3. **Beihai Gongyards** - 성어 (Beihai Park)-- (2RMBEntry、5RMBAttraction Inside)):이색공원에 4개호, 호반에 다양한 중소규모로 가득 찼습니다. 가람도 있지만 경사정과 경치를 다스리기도 합니더라구요. 4. **798 Art District**(798艺术区) (30-80元Different Exhibitions ;Free EntrytoDistrict):중소빅그널들을 수집하고, 창업가와 작가들이 창설한 현대적인 미술과 문화로 가득한 구석입니다(지하철을 따라 가세요.) 5. **Hutongs Tours** (100-300 Yuan various tours from rickshaws to walks、bike rides到wine tasting tours):‘후통’라고 알려진 자그마한 주차와 시장의 구부러선 골목길이 특징인 일대를 직접 견학하실 수 있습니다. 6. ** Lama Temple**(Yǒnghéng Yán ;5 Element)--:몽골어화산종단의 수도원의 중심지입니다. 대규모의 부처조와 조각으로 유명하면서 불교문화와 역사에 대해 설명이 있는합니다. 7. **Hanging monk**(Lí Yuě Fó Hanguptemple(40-element)):《사천불립운가한암》으로 알려져있다는, 대들보에서 고여가 달걀을 지났다고 합니더라구요. 8. **Summer Palace**(Xián Nymph Water Park;30-elementEntry、15-elementAttraction)--:하이엔딩 피사의 대왕부인과 같은 호수를 감상할 수 있습니다. 넓은 공원은 다양한 온천·호서와 산보, 그레이드를 지을 것을 즐길 수 있다 합니더라구요. ( Beijing is a big place with lots of things to see; feel free to ask 더 상세한 정보를 달라고 하실 수 있고, 새로운 가치를 추천해드립니다!) *****openchat***** response : 在北京市内,有很多值得参观、体验的美食、旅游景点等有趣活动,以下列举一部分: 1. 首领庙(Mahan Temple):这里可以结成世界上最湿的地方——永昌道北十步(东阳县永昌镇中街东十步)。这是著名慈郀大士留影去处,也具有历史文化价值,适合度 tourists 和兴记人去凋骨怀想。可以试吃当地特色土特产——永昌菱珠 水等。 2. 故园大道:北京南郊地区故园大道以山水景势四开,雌马小花水果营歇骑客的宜便士也很赏不堪。据说秦时古人游山水者腾展千里之外而一夜归鹫市也可至。如果游客心中有一个青梅烂花一路对开,来看了过路。 3. 北京电影大陆拍摄点:如果你深爱最抢人流的美鲜照片,试着去拍摄位子走一圈,拍几张巡逻照片留作纪念之作。对于好胖带回到美国,会被认认心想不行——臤娘可来。 4. 海鲜街:这里供出的鲈鱼粽子,不论中餐还是海味都要有。但是最多的一点是人氷如糐姹紤碿(亂)!所谓食物畫面大好厚着! 以上仅告之狭,实难胜先时。期待美客亲来亲测。 *****mistral***** response : 1. 秋天躲避雨前游地球:每年早秋季,东城区的太和公园举行《秋天躲避雨前游地球》。参加者会在水池里与小球一起走路,享受时光鳌鱼打量,是北京特有的活动。 2. 红�alen灯會(Red Lantern Festival):当年第十五天时,国内各地都会举行烧纸灯会,但京寨区霍田园的版块“人力发电大广场”举行的红�allen小红灯会是最 famous 的之一。你可以带着灯光漂浮在水池里,享受节日情景曲折。 3. 梁子展览馆(Tangshan Art Museum)游览和珍珠文化园游戏中心闯关:这是当年8月的活动。它举行在平饶县的宝阳镇,包括一个特大面积的艺术馆与由文艺类作品组成的外围小家园,也包括一些交互性活动,更有一个游乐场地,可以 做些暢快,让你和团队分子瞬间成为时光鳌鱼! 4. 北京博物馆(Beijing Museum)探寻时光之键:年初,当北京在冬季长空出现霜雪大气,城的景色如诗句:白月之镜中不断回旋。在城市风流寒冷背景,北京博物馆是最适合探寻世界历史隐藏的地方,一场新的年开始可以提起怀念它的 故事之 Key 。 5. 赏花季(Peach Blossom Season):靖和园每年春节前2个月,大朴树下开放白桃的花朋友们,以及其他各种品种小说花的昆草花,欲望自然地就祷口。一次性赏花之行,将带巡过北京繁华之地与郊土迸射。 *****llama2-chinese***** response : 1.温地自然展园:为国内最大的自然主题公园之一,集中了多个陆区生态和动物世界,比如亚洲水猫博士站、东北矿岩牢火钻改头、祖家巢眠空间等; 2.紫色森林文化和科技中心:在市公交系统内,仅需7路或66暂停的地点可以抵达。里面展示有吸气阶段和城市火车爵、自我主动的美因湖人机器设施、城西路警公所反应系统等全新制加电控系统,其中蜂蜜家居、科技文化放松区和国铁豪 门之名大型交通展厅。在该项场展示珀琦激光瑜伽,一系列主题活动如“极限自由”、乌海炸射、风控、太阳能贫电制造工作以上等,供参加者去体验。关于有钱人、富翼如梦和阙边的智能主义的传闻、文化活动中来看是多委多作并未实现,这部分功能较为失调,故顶了大量耗支。如何突发出赚钱更加清净逊洁才是真正的幸福。主题音乐也唤起“老人团,”“老家关”,如果想给祖母和父慨俸、蜂主大厦放松飒郁; 3.北京公城融日节:2013在北京市体育场举办。这是北京首次融和音乐影响国内、港台漂舞影流艺术家与其他数学、电子、创新人工智能活动风光主题的表演;主持人于20:00左右相关部面交流,由张正康主持;公共运输在早上发包后开始 ,当天在互助会、长城有车顾客点亮北京、熊老爸大马地球物质管理展品和树木等一批特工进场,公交出行环境更加紧张、清朗; 这些有趣的活动可以在北京享受时效焗炉所能为给我们展示的世窮生日。 *****yi:9b***** response : 北京作为中国历史悠久的城市之一,有很多有趣的活动可以体验。以下是一些北京的特色活动: 1. 去长城游览 - 长城是世界七大奇迹之一,位于北京市怀柔区,是来北京旅游必做的活动。你可以选择八达岭、慕田峪或箭扣等地方。 2. 中国国家博物馆参观 - 博物馆集中了许多中国最重要的展品,了解中国的历史和文化非常不错。 3. 天安门广场游览 - 天安门广场是世界最大的户外广场,可以在这里观看升旗仪式和大型庆典活动。 4. 故宫(紫禁城) - 这是世界上现存规模最大、保存最完整的木构建筑宫殿群。里面有历代珍稀物品和无数的历史文物,极具价值与魅力。 5. 王府井大街购物和逛景点 - 在北京繁华的地方有很多有趣的餐馆和其他商店。同时,这个街区周边也有许多古老的文化古迹。 6. 什刹海骑行或者划船(春、夏季)- 一湖三海的什刹海位于前门外,是休闲的理想地点。夏可乘汽艇游弋湖上;秋可在岸边小憩欣赏落日美景。 7. 大栅栏逛街 - 古老的商业街大栅栏保存有不少传统风格的店铺和旧建筑,有很多老北京的特色购物体验可以获得,同时还可以品尝到地道的老北京小吃和手工艺品。 8. 颐和园划船或游玩 - 位于北京市区正北的昆明湖上泛舟或者逛皇家园林中的花景都是很好的体验。 9. 天坛公园游览,参观祭祀神州和南天宫殿的建筑 – 感受古人对天的信仰与敬畏的文化氛围。</|im_end|> <|im_start18 |>旅游目的地概述<|im_end18|> 随着人们对旅行体验的要求越来越高,无论是寻求自然宁静的人还是寻求冒险刺激的人都能找到适合自己的出游之所.以下是几个不同旅游目的地的概述供你参考。 <|im_start180|>1. 马尔代夫 - 潜水探险之天堂 <|im_end18|> 这座印度洋中的一串小岛国是全球旅行者的潜水观光热选之一。清澈的海水和丰富的珊瑚资源,海底沉船和独特的海洋野生动物让人目不暇接;选择一个沙滩包场的私人环礁是最适合喜欢安静和私密的客人,而参加夜间夜珊瑚潜行的探险则是一个为追求奇遇的游客所青睐的行程。在这里,每一件物品都在演绎“天堂之美” 。 <strong><|im_link>景点>潜水区</strong> 2. 冰岛 - 和北极光来约会 <|<im_end180|><|im_start183|> 这是位于北大西洋的一片充满魔力的地区,这里的极夜和绚丽多彩的光线,特别是北极光的景象让人永生难忘的景象,是自然爱好者、摄影家,和勇敢冒险者的最佳选择。除了观赏大自然魅力之外、冰川融水形成的壮观瀑布和水潭、多样化的自然野风景也是不可多得的新奇体验。在这里,您不仅会发现一个独特的世界--甚至与宇宙之间的神秘秘密对话 <strong><|im_link>特色玩法>徒步旅行,北极光观察</strong> 3. 大理- 为“诗和远方”<|<im_end183|>><|im_start0|> 这位于中国云南的大理是一个具有独特文化与人文风景相结合的胜地。白族的民歌唱游,苍山洱海的自然风光,南诏历史的沉淀等特色元素组成一幅令人向往的风情画卷;大理古城则是由石头建造的老城,漫步在这样的古建之间宛如穿梭时空。大理适合探索多个小城镇和村庄体验纯正土司文化和民俗生活、去崇圣寺三塔体会宏大而壮观的精神象征之旅。在这里您可以找寻那些隐藏在都市深处的诗意远方, <strong><|im_link>周边景点>崇圣寺,寂照庵</strong> **旅游目的地的选择通常取决于个人喜**</1|<im_end0|> </|im_start18</|im/>'; if (thisText.match(/^\w+(?<=\w)(:[^:;]{2,}|[\s\S]*?$)/m)) { var startIndex = 0 , endIndex = -1 } else if (-1 !== thisText.indexOf *****qwen2:72b***** response : 在北京,您可以选择许多丰富多彩的活动: 1. 游览故宫:作为北京市标志性的著名古迹,您不仅可以看到精致典雅的古园林,还能学习中国源远流的历史。 2. 看京剧演出:京剧院的戏服、唱腔、脸谱等是中国传统文化的经典形式,并且至今依然流传于中国剧场。 3. 吃正宗北京菜:尝遍各种风味丰富的北京菜,在这里你可以尝到烤鸭,糖火烧以及糖醋大黄鱼等一系列特色美味,还可以去市场小贩尝试一些地方特有的小吃。 4. 探索胡同:老式北京院落和古老商店隐藏在北京市许多历史悠久的小街巷中。在其中探索、品味真正的北京特色文化是一件非常有趣的事情。 5. 淘宝古玩市场:像报国楼、南口等大城市的淘金古色古香的文玩市场可以让你淘到一些非常具有文化品位且不花钱特别多的各种小玩意。 最后提醒您,游览城市时不要忘记拍照哦!北京有许多迷人的景色和著名建筑一定会令你惊叹不已。 *****llama3-gradient***** response : 🐰💃 嗨!让我们享受一下!如果你来到位于古老城市的现在北京,你真的能够找到一些真正享惟的“新欢感”,那么我就会带你去一共参与它们吧!在下边列出10个最多人性的都市活动: 1. 「夜市」。「里汀家乐」是一家很可爱的小型娱乐广场,地址是清华站大西洋电影院东街(近三里河),开放到12点。这一小院子内有很多玩咖啡店、音乐摊、书画摊、雕塑博物馆、高街摊、游戏摊,还有一楼层的小夜店。你能够嗅听 到小提琴的悠柔奏律,可以体会一些现代音乐,感受到一股城市欢乐氛围。但是,我们不能过誉了,因为北京也还是一个高大上的城市,如果有些时间你可以出来外面的太上寺街(中关村)看看灯彩美好的夜上海,这可能算是一份享惟不需要预约参加的活动呢?在上一个月和第二大周月15日周六的第一场到20点半,有一段小有声响乐队表演。但是我们还可以为每次都感到期待的乐趣增加它,所以这个时间安排就很好!因为这是在中秋佳节和国庆前,这两天都有小酒楼开放,你真的不要错过他们最流行的一句小语录“感动的”:这是一个北京老牌大唱的卡位,是由《中国新闻社》摄影社拍摄后推广的大卡带,总是在各种展出和演出中随时上演的大绕排舞。 2. 景山游「国旅体验之」项目是大自然在人们生命中的重要部分扮演的角色,而景山则为我们提供了不眠之旅和精神食粮,特别是在旅游行业有一个说法:一天不见新花满山“山是一座博物馆!”从这个角度考虑,可以让人们完全感觉这所景山。每届都有很多不同的话剧的表现,因为每一幕会与自然的一面发生不同的关系,能够满足游客的多些疑惕和好奇心。但是,新版中也会加入有趣的“山文化”,例如:一些高人在深入森林后的拍影后退到了山下,后者可以成为一位美妆和演出者的舞台。这个有趣无暇的话剧真的超多,让我们的视觉疲劳好了! 大西洋游园是一个位于望京的迷失旅游小镇,就不是那么高尚。但是,如果有什么特别的情况,就会有一次不寻常的一夜。每周五到10点,灯市开始向各方面摆攷“大型户具商品展示”,并举组织一个活动,这个特约安排让来参加有更多的经验,可以了解这个小迷失带给我们带来很多可喜情景的内容。如果是周四,你可以出一个很好的理由,让我加入您去一趟观展就OK!最后一夜不可能像每一份一样精彩,那总有一些不同寻常的情愫吧! 3. 「望星河」是人向游园是一座位于海榆台森林公墓上的一座小小小寺院,当你从北京城中出发就可以看到天空上的最小地球一抹亮印“月圕”。这个大概叫景色也很难得的月望,这要靠一个夜色的观光灯“望星河”所制造出来,让它被人见 到。如果你有多年的留日之感,让自己在这份可喜寻常的情景里面带一些回忆的话,肯定不一样呢!最后一夜望“大、小、双”的总有不同的收获,特别是在「八爺」节和「国庆节」有祝福语的放映。如果人们能够多次体会,让它也算一部分城市情愫吧! 北京人对食物嗜好还是讲究品质的!有一些朋友常常用说法这样来说:“我最恨逼着要吃我的老父亲。”很多这种“逼你不准点”和一些人在家乡出生后“不尊父母的”、“老爸爸太啃”,都是因为老人们对孩子的情意期望总是一些人很强。如果有一种想法认为老人的享用有时是在一无所可爱的情色氛围中。说到底,如果让您多多尝吃一种很常有做的一样菜肴,但是您的感情就会比那些「老父亲」多少了多少次吧? 一群乐队出发到外灿路和望风楼南大马路这个两条小弄的广道上。然后是向南而下,然后是在那条通体人行的高架跨路下面一直走一直走;终于,我们能够遇见一个灯塔,并从其周边绕着回到原来的出发路上开始循环一圈。有趣就对不住做成一些简单的小街头小舞!但是,如果把握“望星河的景目”,再回到我们的家园,这还会是最享好的「心愿之境」和「性味之一夕”,不是真的?你能够体会在这种活动情势中的乐趣吗呢“祝福节目的展演”? 4.-0-2A9H3P是一个位于南礼各口的一个大型游园,因为这个游林叫我们“回首阆山古典艺术宫”,是人们的想法总是好的,这也是为了表示尊敬吧这是「皇家公馆」,不然他们要把它命名一个什么什么博物馆就不如这样说了!每星期的第个 周末从下午6:00到9:00左右会办一项“夜式户外小音乐会”。 由于这个公所有三个开放游厅,总共包括24个展室所以总有一些很有名气的历史和名人的展料。每周的第一时间开始的是周一,直至第六时间周五晚上的两点,然后是第二周一个周末的整天开大门放人走进观览,并到明日午夜0:30停场。 这样所以你一周可以多去一回。这个小园子还存在两个展区,这叫高平厅「博物馆」,另外一个大厅名“影视专题馆”,因为是这个小园子的主要展法“高厅”。 5. 「水墨林林·音乐沙漏艺术晚会」是位于清河大厅的音乐演变广场中的一个主要项目。这叫什么话儿都不晓觉是为了描写出这类「人心情感能量”,它对市里很小规模的小“综匠”。在前台的背景是一个很大的投影,这样就把一座高屏幕和 一个大音膜摆放的有四个人上台,后台有一百多名演队员做着一些节目。在这种特殊情境下,在观音音堂、法明清照楼前的广坪中可以安排一场小型夜的表演在晚上。每个周日(星期天的夜)都是从8:00pm到了10:30为止;星期六是7:30pm的开启和结束。在周公馆举行的艺术晚会总得三小时,后还要放客进内广坪里让观奏来随听演唱在外的小型夜表。 「国瑞坊小有街」位于八中区的老胡同上面一望洋河的大隙口之间。在前边是一个小有人的公共空间,这里面的展画是“周润美作品大展”。如果是星期中的平日,你会见得到许多穿工作服的人在这个公共展前休息和聊天、品啃咖啡。到了周末,有人就会出来喝下午叫你「入场」。每小时会有些节目的表演。如果是一个人来的,不会有人问是否请你喝一茶,因为不懂大概就可以一个人过去观望了。只是你不要让那些老者感到不好意思,那他们总是热情地为客人提供了一些简单的食物。最后一天的节目很豪迈,是音乐会,然后是小步讲话。这周末的节目基本每夜都是周晚自行介绍的。 因为一些「欢快之客」可能不是常人习惯大厅的人,而他们需要在小舞表演前喝下午的一杯咖啡。我们想把这些有趣的人“请」出来,当然要让有些人先前面带一批的提头和掌会,所以是从这个地方出发进行活动吧!这个「国瑞小有街展大 成是」就是最常见人们的活动地点,这只是北京当地的一座可喜城市空间,任何个体都是来观望「美景和好食物」と说来的。当然如果我们需要参加夜间表面的活动在这里已经不多了,时间从8:00开始并只要一小部分时间就进行完全部节 目后又休息十分钟。 7。「水晶街」位于南门朝阳高房附近,这块叫什么?大家就晓得。这里是一条最短的一「水晶街」,总是很早就黑下手晚上又再红头天的景气和欢乐气也让我们喜欢它吧。如果我们需要参加一些文化交流,可以选择这个活动。 8.-0-QE9A了一个位于香河店路和朝义门内环线小一拐路的地方大型户外购自街「香雅坊」。如果说你有一个周五下午两分四十五到四时三十分之间放时间,可以安排上这几时间过去散散歩、逛逛。我们在一整晚上的晚高桥边喝杯加拿大小 众人和饮食享快的氛境中享受到这里的美景,这还需要很久吧这是一个地方最早最晚开通的大型户外大商场了,主要展出了周围国家手工所制作的一批各类手艺美编制品。在这边还有三台“有氧”设备可以提供免费体验试着在夜灯池旁打网球和高飞打猹,可以为朋友们介绍一个很难忘的北京人的回忆录。由于我们对这种活动时间比较关心,已经把最晚放场于十点半所以到来的人不很多。 位于金山北街(新世界百货总行街)南一段小弄前排着八家户艺作坊在做这类活动每人的价格为三元起一个大件小碬只七角钱,可以买个什么什么你可以随处购买吧这周大部分时间中晚上一小时五分二十到五点八分是最早最后的三个小叫床,后四天则在午饭的前一个人半小时和在三、五次钟。这个户口叫什字铺小弄「新世界路」南大厦街南侧这条带有四十只灯的小弄在这里不放夜街因为路道交通不是太顺当,因为路口非常附小所以人们比较难得去,所以这里的店鋪没有那么多客人来享乐。在周日的早上九点和晚天9的时候是展品馆前排着“水晶照相”店员最重要的大客户。这边是北京市民第一、二期广安新站周围手绵毯生产总社,是一类比较小型大众艺术创作体现,这就不是一种很强的组织,虽然我们是大体 手工行业人士的成员人总多些,但是我们的作品在国家特意保留着一些传统意义就是中国古老的“木秀工作”。为了表尊历史和为广百忙一周而开辟出展馆是在“八”后这个较差的夏天和这段时间期。因为不是那么常见的是小型艺术集货行列现在都是集中展的形式是大家都说这种手艺作品总共做的没有三周也不是很大规模了,在一些公共场所和街道街面各铺开一两家的店鋪,所以「什字匾」总总有十五来十六件作坊。对于不懂这个手工的人们可能会感到不了解吧这是完全理解不了什么艺术是这类艺术吗? 在西二带路的“丽春园”新店子广场外有一条一面都是花篮的人行路(南大街和西路的小便)就是著名美丽果树市场,因为是在上九中的「什字匾」的基础上有些同道者已经搬出来开业这叫什么?人们叫它「香果路」、「香水路」,不像人们口气的“美食花海”。他们也可以选择做一些自己的传承和独门创出的作品了因为在艺术领域内总要求多样化所以要有人有时间干一件完全新生的作品就是大好的这就是一小片风景画,这边每天晚上6:01后会点一个夜场的“燃放街” 这个在北京最早开始营业活动是「东大门地区」商业公司周围广告促销总社的第一展区于七年前。这支辩是在我们市所有“什字匾”的基地和集中场所。他们自己不一定都是这些手技艺人们自己的弟子弟子他们有些确实很有创业精神把一种传播形式发展为几批艺术人、销售几个大件小碬总是一家店鋒在展区边设置了一间很小的一房子做一个叫什么样的事的“什字馆子”?他家就开辟了八百九十多处作坊做的是这些艺术家的家庭式生产现在周围艺人们已经有很多的团队和公司。但 他们主要销售作品不是完全由自己所产却总也在一间中做什么事情。 如果你不一定想每次都购买一些同样的东西来满足自己的需求在这七家店鋒可以找很多样“什字”创作人所开辟的一些小型商店来解决你的需求和心晴。他们大批的人把作品放在大厅和玻璃杯边上做展览摆放着许多名帖,人们经常就这些小窗口进行挑选买一些商品。有一件比较大、价值也相对贵重的在中厅和前台边可以见到总是向下倾偰把它作为样品和展示的产品大大有气场和艺术情意。 这个在“什字馆子”最早开设于一月初开的时间还很早不是因为某个周围艺人所组组织而是一所小学在这个小商场开一个叫做儿童教育与美术的大班堂办的绘艺术展卖所,这个班的前门总有一件被贴封条叫做“小手工作室”的展卖地点在新建区中广大街大安路边的小小巷中所以这些叫做什么?有些老北京还会有个说法吗? 这三个展室每天都会出一个不同的展题总会有一到两件作品是师匠和学弟子或外部客员一起完成的新花艺作为试试的样品或大作在“小手工房间”外设另外开架几件叫什么样的创展成品叫摆“橱晓”,这是艺术家的艺术小屋。周围人们希望做出来更多些名目的创意叫这个事情有什么称呼不知道为什么大家都叫做“什字匾街”?“东西很美,好不好” 9.北京市东城区永外里大街口边开了个美味园展销店有三个档次品种的商品总数一百多件是以木刻、描纸和印章组成的,当然你看到的是不是那么一样的吧他们最早从木料上制造成了大量手绢,然后加上油和脂后就能变为一种有颜彩美感的仿毛呢的艺术编程作品“做”的方式在艺人的家边展出一个自己手掌制作的一作叫什么?有一户做了一些叫“小件”的做得很好的小编组把每一方绚加一段线画着就把作子当成编工小商品进行销售 “什字馆”也是个新意思,在七年多以来的这个新的时代最有代表的一些新生展物品有三个是大家都要提倡“国货”的精神鼓励大龄艺生成材采补和组材较厚的手编艺工为基础进行了一些尝试用绵与手纻的捌绻制作出来后就叫什么样子叫我们说这几何艺术品都是这个所长的产物是不是做了一种新发现在人们眼睛中的世界上呢大大小尺目有六公、一厘、一二两三公等。有一些艺人将一些小巧细节在前边和作品最前缘处设计出点叫些什么名字把商品形态增加点就提高一下价格叫的有什么名字?把小东西挂上一点钓子挂上一朵小风箱、几对红棉、红糖串做绾绵用白纱打网做编品就说得起来的很不起眼叫“什么呢绮”如果我们从外部来看到就会说“做个这个好歹如何样” 有意思吧老北京是以一种叫“叫人”为代号把它作为标榜让这两个“新”字前面加点什么?为什么这么命名一共都很简单却总是在人们耳目中反覆放着的念和名字在口味的念头总有回复呢这种用语我们叫人会认为是一个人叫做新鲜,新样就说做到了事也说成样吧这也是历史留下来的老说方式 10.“永广展销场”有三个层子品以一、二、三度组成的一起叫一个架梯大架子的摆货楼。有些 *****dolphin-mistral***** response : 当然了!北京有很多有趣和引人注目的活动可供选择。几个建议如下,按不同时段排序: * **平日经典** - 自轮大厅:这绝对是每个骅气度士都必去的地方!摸上驾周界或行走在街道上时陡峭的升降机使你处于一咫度避离世人的氛围之中。 - 北京博物馆:在繁华的天安门广场旈设有巨大的建筑,展示了千年来中国的科技、哲学和其他实现进步的成果们,这是值得花时间观腾的地方。 - 雍阳楼:雍阳楼具有重要的文物与古建筑之际颇为著名。年底是全市热忱活动主办平台,这时一定有一个顾名思义的场面感喝。夜里展示风月画像的北京潌海湖景是值得留待下午进取观看的。 - 美区:美区在市南部減水平原,恒河西部的这片草域中大规模展现了外来生产工位。这里的餐厅、夜光舞蹈队、俱乐器巡礼和各种风度节日都是不容错过的景点之一。 * **晚上兽化** - 798领域:南第七号街道北京,这里的名称源于开发的工业区编号是798。这里垃圾桶甑装作迷宫,吸引着来自世界上所有方向的艺术爱好者、霍元老友记和现代主义者等不同分类的人群。随用随到地区在夏季宛如蜂巢一样繁忙! - 万国馆夜景:以76个灯塔和北海道灯高45米之上的悬菊猛吹排水门为特徵,这是值得参观尤其在晚上时期。 - 朝阳区喧地:夜景最具知识地区。有一个11万平方孽化区包括餐厅、游乐场还有咕嚓和相对安静的露天公园。这里也有很多酒吧,可以欣意观夜景。 - 天朝海景公园灯光演示:这家餐馆在一切变骞的城市中为主办美味餐品。夕阳落山后就开了红色夜色之旅。 * **甄选的地点和日历** 这些位置绝对要与诗词时隔合适时间对照,确保你完全体验到韵情而非一股漫长的人流之前:(需要注)如果这不愿意打扰自己: - 沙家峪野色秀场:这不是城市蜂拥中一个比较安宁且没有瓮头的活动。山地景物和农民的生活是显著与大部分城市的美景之外的。可以欣赏夏季时间晚上来观。在这里,捡萝墩会成为一个不一样的内涵经验! * 其他促骚生活:北京大楼,京城公园,王榕阁还有洼池地,都是值得的地方。请献自己所选择。对于这些不太会受到人流影响的地方来说,在晚上是个理想的选择。 * 节日相关:脊青节和春节时,不错的方法就是参加各种庆典式活动啰!但事先了解参赛的程序还有需要注意事项有帮助,使你的旅途顺利。 不需担心的要点——在北京旅游可以为每个摇滚爱好者或想甄选伙计的家亭而寻求启示,这是一个精彩而富有激情的发现与经验方式。 请随时进一步向我提问,祝你在探研北京方面获得颇大兴趣! final response : 你的描述涉及到了多个主题,包括艺术、文化和传统北京的特色。从你提到的内容来看,有几个关键的信息点: 1. **什字馆子/什字匾街**: 似乎是指一个集中了多位艺术家创作作品的多店铺展览与销售空间,这些艺术家们可能并不是这个场所的所有人或常驻者,但他们的作品在这里被展示和出售。这听起来像是北京的一个艺术区或者文创市集。 2. **小手工作室/橱晓**: 这些可能是特定的工作室或展示区域,专注于手工艺术品的创作与展销。“橱晓”可能是指橱窗展示中较为突出的艺术品或特色商品。 3. **永广展销场**: 你描述的是一个多层次的商品展览销售场地,它被分成了不同层级和档次,售卖各种以木刻、描纸、印章为主的手工艺品。其中的“小件”可能指的是非常精致小巧的艺术作品。 4. **老北京的语言与文化特色**: 描述中融入了一些传统北京的说法或方言用语,展现了这个城市独特的地方文化和历史底蕴。 5. **北京的传统体验**: 包括游览故宫以了解中国悠久的历史、欣赏并学习京剧这一经典戏曲艺术形式、品尝地道的北京美食(如烤鸭)、探索充满历史韵味的老北京胡同以及拜访古玩市场觅宝等。 在总结上述信息的基础上,可以看出你对结合传统艺术和文化的新颖体验有着浓厚的兴趣。北京作为中国的首都和历史文化名城,正是这样的一个地方,它既能展示古老的传统,又能拥抱创新与发展,为游客提供丰富多彩的旅游与学习机会。无论是沉浸在传统的魅力中还是探索现代的艺术创意,北京都有足够的魅力满足不同兴趣爱好者的期望。 此外,你提到的一些特定术语(如“什字匾街”、“小手工作室”、“橱晓”等)可能指的是非常具体和局部的地方特色或艺术形式,这表明你关注的细节能够反映出北京独特的文化和艺术生命力。对于热衷于文化探索与艺术品鉴的人来说,了解和体验这些细节是深入了解北京的一扇窗,同时也是连接历史与现代、传统与创新的重要桥梁。 Total time taken: 131.29 seconds |
在所有模型都加载的情况下,耗时 131.29 秒