此环境提供了 vLLM 服务引擎的高性能部署,该引擎针对大规模服务大型语言模型进行了优化。
特征
- 预配置的 vLLM 服务器,可以运行您指定的模型
- 兼容 OpenAI 的 API 端点
- 通过环境变量轻松配置
- 支持自定义SSL证书
- 内置基准测试工具
能力
在我们的 1x RTX 3090 实例上对 Llama 3.1 8B (fp16) 进行基准测试表明,它可以通过在 100+ 并发请求下实现每秒合理的令牌数来支持拥有数千用户的应用程序。
下图显示,对于 100 个并发请求,每个请求最坏情况 (p99) 为 12.88 个令牌/秒,导致总令牌数为 1300+!
每秒 P99 个令牌
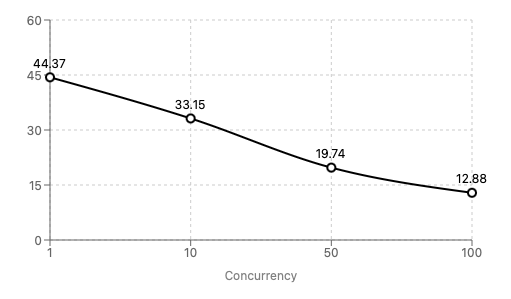
请注意,这使用了一个简单的低令牌提示,实际结果可能会有所不同。
使用服务器
可以通过以下 URL 访问 vLLM 服务器:http://<your-instance-public-ip>:8000/v1
将 <your-instance-public-ip> 替换为 Backprop 实例的公共 IP。如果已配置,请使用 https。
示例请求:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
curl http://<your-instance-public-ip>:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -H "Authorization: Bearer token-abc123" \ -d '{ "model": "NousResearch/Meta-Llama-3.1-8B-Instruct", "messages": [ { "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": "Translate to French: Hello, how are you?" } ] }' |
有关详细信息,请参阅 vLLM API 参考。
配置
您可以使用以下环境变量自定义 vLLM 服务器配置:
MODEL_NAME:要加载的 Huggingface 模型的名称(默认:“NousResearch/Meta-Llama-3.1-8B-Instruct”)API_KEY:用于身份验证的 API 密钥(默认:“token-abc123”)GPU_MEMORY_UTILIZATION:GPU 内存利用率(默认:0.99)TENSOR_PARALLEL_SIZE:用于张量并行的 GPU 数量(默认值:1)MAX_MODEL_LEN:最大序列长度 – 值越低,使用的 GPU VRAM 越少(默认值:50000)USE_HTTPS:设置为“true”以启用具有自签名证书的 HTTPS(默认值:“false”)
您可以在启动环境时更新这些变量。
自定义SSL证书
如果要使用自定义 SSL 证书而不是自动生成的证书,可以替换以下文件:
/home/ubuntu/.vllm/ssl/cert.pem:您的SSL证书/home/ubuntu/.vllm/ssl/key.pem:您的 SSL 私钥
替换这些文件后,重新启动 vLLM 服务以使更改生效。
高级配置
要更新 vLLM 服务器配置,请执行以下操作:
- 根据需要修改环境变量(见上文)。
- 如有必要,请编辑 systemd 服务文件:
sudo nano /etc/systemd/system/vllm.service
- 进行更改后,重新加载 systemd 守护程序并重新启动服务:
sudo systemctl daemon-reloadsudo systemctl restart vllm
查看日志
要查看 vLLM 服务器日志,您可以使用以下命令:
|
1 |
sudo journalctl -u vllm -f |
这将向您显示 vLLM 服务的实时日志。
标杆
此环境附带内置的基准测试工具(请参阅 repo)。您可以在 /home/ubuntu/vllm-benchmark 目录中找到基准测试脚本。
要运行基准测试,请执行以下操作:
|
1 2 3 4 5 |
cd /home/ubuntu/vllm-benchmark python vllm_benchmark.py \ --vllm_url "http://<your-instance-public-ip>:8000/v1" \ --api_key "your-api-key"\ --num_requests 100 --concurrency 10 |
更多文档
有关 vLLM 及其 OpenAI 兼容服务器的更多详细信息,请参阅官方 vLLM 文档。