概要
函数调用代理模型的进步需要多样化、可靠和高质量的数据集。本文介绍了 APIGen,这是一种自动化数据生成管道,旨在为函数调用应用程序生成可验证的高质量数据集。我们利用 APIGen 收集了 21 个不同类别的 3673 个可执行 API,以可扩展和结构化的方式生成不同的函数调用数据集。我们数据集中的每个数据都经过格式检查、实际函数执行和语义验证三个分层阶段进行验证,确保其可靠性和正确性。我们证明,使用我们精选的数据集训练的模型,即使只有 7B 参数,也可以在伯克利函数调用基准上实现最先进的性能,优于多个 GPT-4 模型。此外,我们的 1B 模型实现了卓越的性能,超过了 GPT-3.5-Turbo 和 Claude-3 Haiku。我们发布了一个包含 60,000 个高质量条目的数据集,旨在推进函数调用代理域领域。
论文
数据
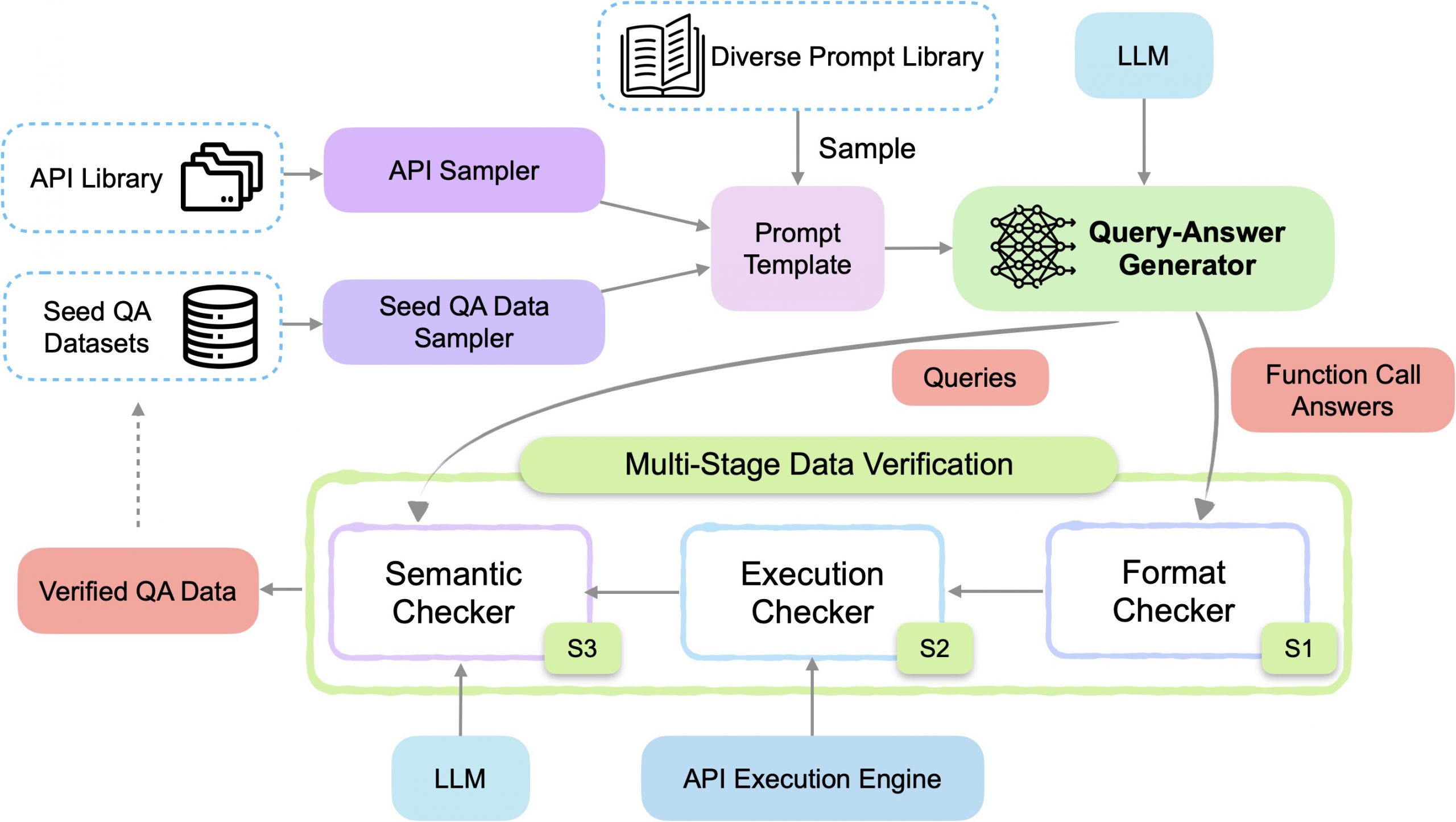
框架
本节介绍APIGen的详细设计,APIGen是一个用于生成可验证和多样化的函数调用数据集的自动化流水线。我们的框架在设计时考虑了三个关键因素:数据质量、数据多样性和集合可扩展性。我们通过下图所示的关键模块实现这些目标:多阶段数据验证过程确保数据质量,种子QA(查询-答案)数据采样器、API 采样器和各种提示模板确保多样性,我们使用统一格式的结构化模块化设计使系统能够扩展到不同的 API 源,包括但不限于 Python 函数和具象状态传输 (REST) API。
数据生成概述
使用 APIGen 框架的数据生成过程首先从库中抽取一个或多个 API 和示例查询-答案 (QA) 对,然后将它们格式化为标准化的 JSON 格式(示例见下图)。根据所需的数据生成目标选择提示模板,引导 LLM 生成相关的查询-答案对。生成的对中的每个答案都是以 JSON 格式化的函数调用。

对 API、函数调用和生成器输出采用标准化的 JSON 格式具有多个优点。首先,它建立了一种结构化方法来验证生成器的输出是否包含所有必要的字段。不符合这些格式要求的输出将被丢弃。其次,JSON结构可以有效地检查函数调用的正确解析和参数的有效性。将排除包含 API 库中不存在的参数或幻觉不存在的函数的调用,从而提高数据集的整体质量。另一个关键优势是它支持的可扩展性。有了这种统一的格式,APIGen 可以很容易地合并来自不同来源(Python 函数、REST API 等)的数据,方法是开发格式转换器,将它们改编成这些基本的 JSON 元素,而无需修改其他核心组件,例如提示库,使框架具有高度的适应性和可扩展性。
生成的函数调用经过多阶段验证过程,以确保其正确性和相关性。首先,格式检查器验证正确的 JSON 格式和可分析性。接下来,API 执行引擎处理调用,并将结果和查询发送到语义检查器(另一个 LLM),用于评估函数调用、执行结果和查询目标之间的一致性。通过所有阶段的数据点将作为高质量示例添加回种子数据集,以增强下一代的多样性。
多级数据验证
优先考虑质量至关重要,因为先前的研究表明,少量的高质量微调数据可以大大提高模型在特定领域任务中的性能。这促使我们的多阶段数据集验证过程有效地对齐大型语言模型。
推动我们框架设计的关键见解是,与难以评估的合成聊天数据不同,函数调用答案可以通过其相应的 API 直接执行。这样可以检查输出 API 和参数的格式是否正确、生成的 API 调用是否可执行,以及执行结果是否与查询的意图匹配等。基于这一观察结果,我们提出了一个三阶段验证过程:
- 第 1 阶段:格式检查器:此阶段执行健全性检查,以筛选出格式不佳或不完整的数据。LLM 输出必须严格遵循带有“query”和“answer”字段的 JSON 格式。此外,还会检查函数调用是否正确 JSON 分析和有效参数。如果参数或函数在给定的 API 中不存在,则将消除生成的调用,以减少幻觉并提高数据质量。
- 第 2 阶段:执行检查器:阶段 1 中格式良好的函数调用将针对相应的后端执行。将筛选出不成功的执行,并为失败提供细粒度的错误消息。
- 第 3 阶段:语义检查器:成功的第 2 阶段执行结果、可用函数和生成的查询将被格式化并传递给另一个 LLM,以评估结果在语义上是否与查询的目标一致。通过所有三个验证阶段的数据点被视为高质量,并重新添加以改进未来多样化的数据生成。
提高数据集多样性的方法
鼓励训练数据集的多样性对于开发能够处理各种真实场景的健壮函数调用代理至关重要。在 APIGen 中,我们从多个角度促进数据多样性,包括查询样式多样性、采样多样性和 API 多样性。
- 查询样式多样性:APIGen 的数据集分为四大类:简单、多、并行和并行多类,每类都旨在挑战和增强模型在不同使用场景中的能力。这些类别由相应的提示和种子数据控制。
- 采样多样性:APIGen 利用一个采样系统,旨在最大限度地提高生成数据集的多样性和相关性。这包括 API Sampler、Example Sampler 和 Prompt Sampler。
在 APIGen 中,每次数据集迭代采样的示例和 API 数量是从预定义的范围内随机选择的。这种随机化通过防止重复模式和确保场景的广泛覆盖来增强数据集的可变性。
数据集 API 源
为了确保高质量和多样化的数据集,我们专注于收集可以轻松执行的真实世界 API,并附有详尽的文档。我们主要从 ToolBench 获取 API,这是一个全面的工具使用数据集,包括 RapidAPI Hub 的 49 个粗粒度类别的 16,464 个 REST API。该中心是一个领先的市场,拥有大量开发人员贡献的 API。
为了进一步提高 API 的可用性和质量,我们对 ToolBench 数据集执行以下过滤和清理过程:
- 数据质量过滤:我们删除了文档解析不正确的 API 以及缺少必需或可选参数的 API。排除了不需要参数的 API,以保持适合我们数据集需求的挑战级别。
- API 可访问性测试:我们通过使用数据集中提供的示例参数和通过 Stable Toolbench 服务器向每个端点发出请求来测试 API 可访问性。无法执行或返回错误(例如超时或无效的端点)的 API 将被丢弃。
- 文档字符串再生:为了提高 API 文档的质量,我们为具有嘈杂和不可用的描述的 API 重新生成了文档字符串。
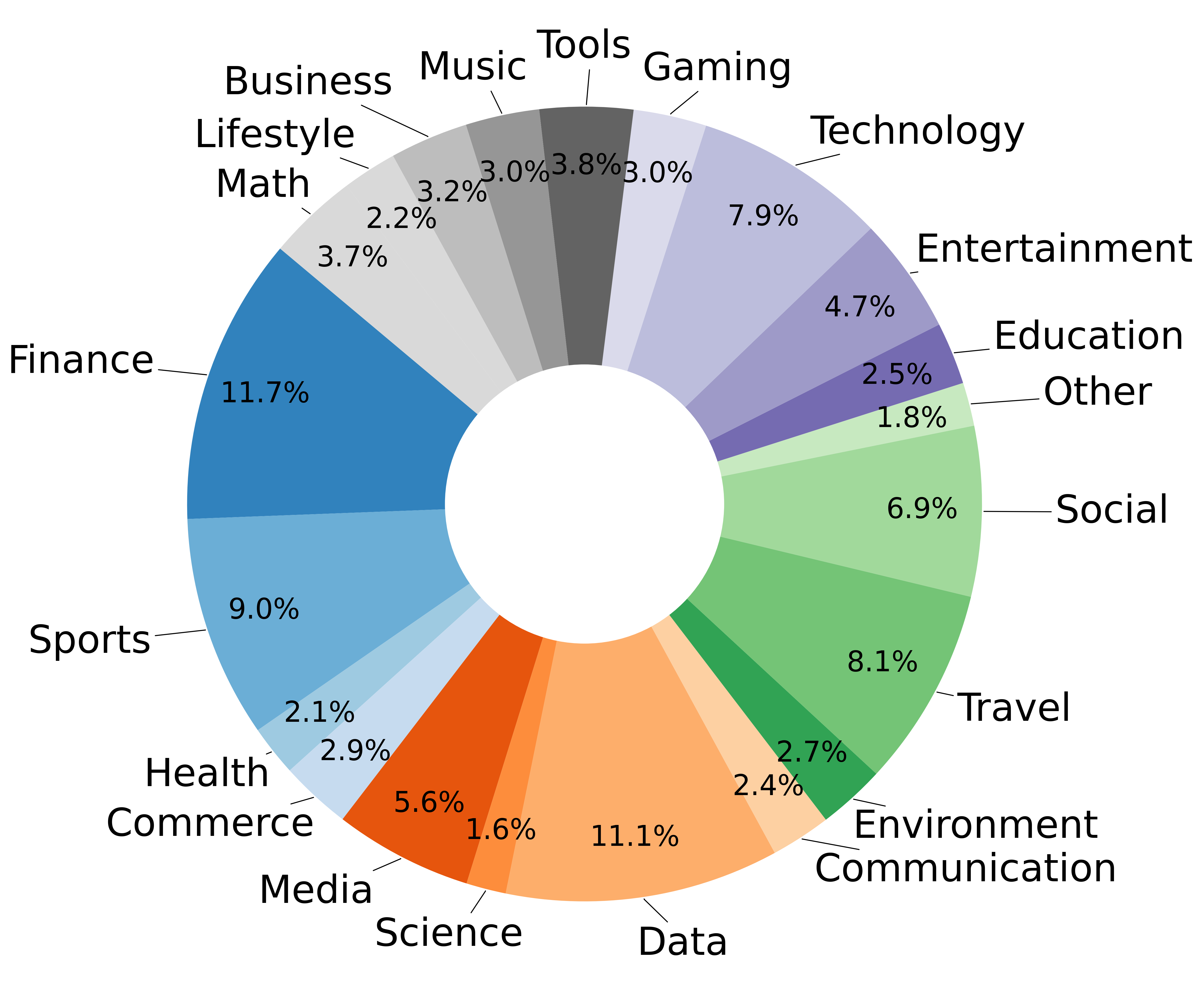
清理后,我们获得了 3,539 个可执行的 REST API,并附有良好的文档。此外,我们还将 Python 函数作为另一种 API 类型,其灵感来自 Berkeley 函数调用基准的可执行评估类别。我们收集了 134 个有据可查的 Python 函数,涵盖数学、金融和数据管理等不同领域。补充材料中提供了示例 API 示例。
原始 ToolBench 数据集包含语义上重叠的类别,例如 Finance 和 Financial。我们将这些合并为 21 个不同的类别,以确保整个数据集的清晰度和平衡性。图显示了 3,673 个可执行 API 在这些重新定义的类别中的分布情况,涵盖技术、社会科学、教育和体育等领域。这种多样化的 API 集合为合成数据生成提供了坚实的基础,是确保数据质量和可靠性的宝贵资产。
集合设置和数据集详细信息
为了验证 APIGen 框架的有效性,我们生成了针对各种查询样式的数据集。我们利用几个基本的 LLM 来生成数据,包括 DeepSeek-V2-Chat (236B)、DeepSeek-Coder-33B-Inst、Mixtral-8x22B-Inst 和 Mixtral-8x7B-Inst。对于每个模型,我们的目标是通过对 API、种子数据和提示模板的不同组合进行采样来生成 40,000 个数据点。为了促进生成响应的多样性,我们将所有模型的生成温度设置为 0.7。补充材料中提供了所用提示模板和 API 的示例,以供参考。
下表显示了不同模型的数据生成过程的统计数据,包括验证数据点总数和每个验证阶段的过滤数据点数。由于格式问题、执行错误或未能通过语义检查,筛选过程成功删除了许多低质量的数据点。前两个阶段,格式检查器和执行检查器,通常会过滤掉大多数低质量的数据。这些数据点通常具有不可行的参数范围、不正确的类型、缺少必需的参数或更严重的问题,例如函数调用或参数的幻觉。我们的系统验证流程提供了一种严格的方法来减少这些情况的发生。
| 型 | 可信数据 | 失败格式 | 执行失败 | 失败语义 | 通过率 |
|---|---|---|---|---|---|
| DeepSeek-Coder-33B-Inst | 13,769 | 4,311 | 15,496 | 6,424 | 34.42% |
| 混合-8x7B-Inst | 15,385 | 3,311 | 12,341 | 7,963 | 38.46% |
| 混合-8x22B-Inst | 26,384 | 1,680 | 5,073 | 6,863 | 65.96% |
| DeepSeek-V2-聊天 (236B) | 33,659 | 817 | 3,359 | 2,165 | 84.15% |
语义检查器在过滤与查询目标不一致的生成数据方面也起着至关重要的作用。例如,如果用户的查询包含多个请求,但返回的结果只针对一个请求,或者如果生成的函数调用数据和执行结果与用户的查询不匹配,则该数据点将被过滤掉。如实验所示,在模型训练的训练集中包含这些数据点可能会损害性能。
我们观察到,像 DeepSeek-V2-Chat 和 Mixtral-8x22B-Inst 这样更强大的模型具有更好的格式跟踪能力和更高的通过率,而两个相对较小的模型产生无法执行的数据的可能性要高得多。这表明,当使用较弱的模型生成数据时,建议进行严格的验证过程以过滤掉低质量的数据。
我们将发布大约 60,000 个高质量的函数调用数据集,这些数据集由两个最强的模型生成:Mixtral-8x22B-Inst 和 DeepSeek-V2-Chat (236B)。这些数据集包括提到的所有查询样式,涵盖了广泛的实际情况,具有 21 个类别的 3,673 个不同的 API。每个数据点都使用真实世界的 API 进行验证,以确保其有效性和有用性。通过公开该数据集,我们旨在使研究界受益,并促进该领域的未来工作。