隆重推出 OpenDiLoCo,这是 DeepMind 分布式低通信 (DiLoCo) 方法的开源实现和扩展,可实现全球分布式 AI 模型训练。
上周,我们发布了总体规划的第一步,启动了Prime Intellect Compute Exchange,以聚合和编排全球计算资源。
今天,我们很高兴地宣布,通过开源我们的分布式训练框架,在第二部分向前迈出了一大步,以实现跨全球分布式硬件的协作模型开发。
我们提供 Deepmind 的 DiLoCo 实验的可重复实现,并在可扩展的去中心化训练框架内提供。我们通过在两大洲和三个国家/地区训练模型来证明其有效性,同时保持 90-95% 的计算利用率。此外,我们将 DiLoCo 的大小扩展到原始工作的 3 倍,证明了它对十亿参数模型的有效性。
论文:https://arxiv.org/abs/2407.07852
代码:https://github.com/PrimeIntellect-ai/OpenDiLoCo
OpenDiLoCo 训练运行可视化
大型语言模型已经彻底改变了人工智能,但传统上训练它们需要大规模的集中式计算集群。这种资源的集中限制了谁可以参与人工智能的发展,并减缓了创新的步伐。
最近,我们发表了一篇详细的博客文章,探讨了去中心化人工智能训练的最新技术。在这篇文章中,我们重点介绍了最有前途的方法和仍需要克服的几个关键挑战:
- 缓慢的互连带宽
- 确保容错培训
- 非同构硬件设置
- 还有更多…
OpenDiLoCo 是我们的研究工作之一,旨在通过促进全球多个连接不良设备的高效训练来克服这些挑战中的第一个挑战。
主要贡献
- 复制和扩展:我们已经成功地重现了原始的 DiLoCo 实验,并将其扩展到十亿参数模型规模。
- 开源实现:我们正在发布一个基于 Hivemind 库的可扩展实现,使广泛的开发人员和研究人员都可以进行去中心化培训。我们的框架通过与 PyTorch FSDP 的集成,使单个 DiLoCo 工作人员能够扩展到数百台机器。
- 全球去中心化训练:我们通过在两大洲和三个国家/地区训练模型,实现了 90-95% 的计算利用率,展示了 OpenDiLoCo 在现实世界中的潜力。
- 效率洞察:我们的消融研究为算法的可扩展性和计算效率提供了宝贵的见解,为未来的改进铺平了道路。
DiLoCo
Google DeepMind最近的工作引入了一种方法,可以在连接不良的设备孤岛上训练语言模型。这种方法允许在这些不同的岛屿上进行数据并行训练,只需要每 500 步同步一次伪梯度。
DiLoCo 引入了一种内外优化算法,允许本地和全局更新。每个工作线程使用本地 AdamW 优化器(内部优化)独立地多次更新其权重。每 ~500 次更新,该算法就会使用 Nesterov 动量优化器执行外部优化,该优化器同步所有工作人员的伪梯度(所有局部梯度的总和)。
这种方法大大降低了通信频率(最多 500 次),从而降低了分布式训练的带宽要求。

OpenDiLoCo
为了促进在这个有前途的研究方向上的合作,使人工智能民主化,我们在开源许可下发布了 OpenDiLoCo 代码:https://github.com/PrimeIntellect-ai/OpenDiLoCo。
我们的实现建立在 Hivemind 库之上。Hivemind 没有使用 torch.distributed 进行工作线程通信,而是利用分布在每个工作线程上的分布式哈希表 (DHT) 来通信元数据并同步它们。此 DHT 是使用开源 libp2p 项目实现的。我们利用 Hivemind 进行 DiLoCo worker 之间的节点间通信,并利用 PyTorch FSDP 进行 DiLoCo Worker 内的节点内通信。
我们与 Hivemind 的集成为 DiLoCo 提供了真实世界的去中心化训练设置,使其许多固有属性可用,例如:
- 资源的开/关斜坡:在训练期间,可用计算量可能会有所不同,新设备和集群会在训练过程中加入和离开。
- 容错:对于分散式培训,某些设备可能不如其他设备可靠。通过 Hivemind 的容错训练,设备可以在不停止训练过程的情况下随时变得不可用。
- 点对点:没有主节点。所有通信都是以点对点的方式完成的。
主要结果
作为第一步,我们复制了DiLoCO的主要实验结果。我们使用 C4 数据集在语言建模任务上训练了一个具有 1.5 亿个参数的模型。
我们发现,尽管通信要求降低了 500 倍,但具有 8 个副本的 DiLoCo 明显优于没有任何副本的基线,并且在相同的计算预算下与更强的基线的性能相匹配。
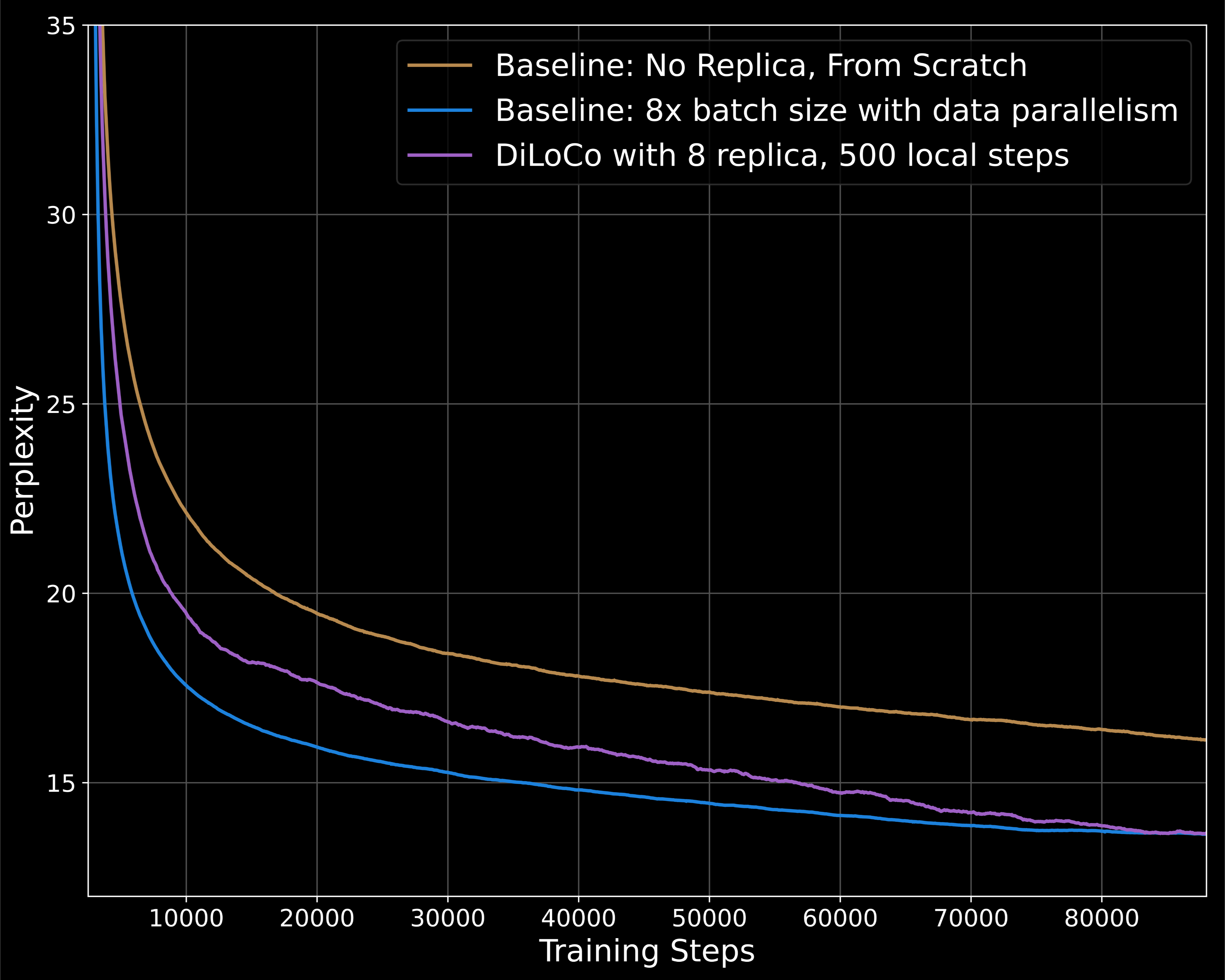
除了复制结果外,我们还对 DiLoCo 进行了几项消融研究,重点关注算法的可扩展性与工作线程数量和计算效率。我们还证明,在FP16中,DiLoCo伪梯度可以有效地全部还原,而不会降低任何性能。
有关更多详细信息,请查看arXiv上的论文。
将 DiLoCo 扩展到十亿个参数模型
DeepMind 最初的 DiLoCo 论文只试验了多达 4 亿个参数的模型大小。在我们的工作中,我们将该方法扩展到具有 11 亿个参数的模型。我们采用与 TinyLlama 相同的超参数,并使用包含 800 万个令牌的总批大小(批大小为 8192,序列长度为 1024)。由于与我们之前的实验相比,批量大小增加了 4 倍,因此我们决定只为这个实验训练 44k 个步骤。
我们将结果与两个基线进行了比较:一个没有 DiLoCo 和没有副本的弱基线,以及使用具有数据并行性的 4× 大批量的更强基线。
当使用 500 的局部步长(每 500 步在工人之间同步)时,类似于 1.5 亿参数模型的实验,我们在训练的早期阶段观察到次优收敛。训练动态在训练的后期阶段有所改善,如果我们进一步训练到 88k 步,可能会符合我们的基线。
我们还进行了一项局部步长为 125 的实验。在这种制度下,在训练的早期阶段,训练动态实际上更好。具有 125 个本地步骤的 DiLoCo 运行几乎与相同计算预算下的更强基线的性能相匹配,而通信量减少了 125 倍。
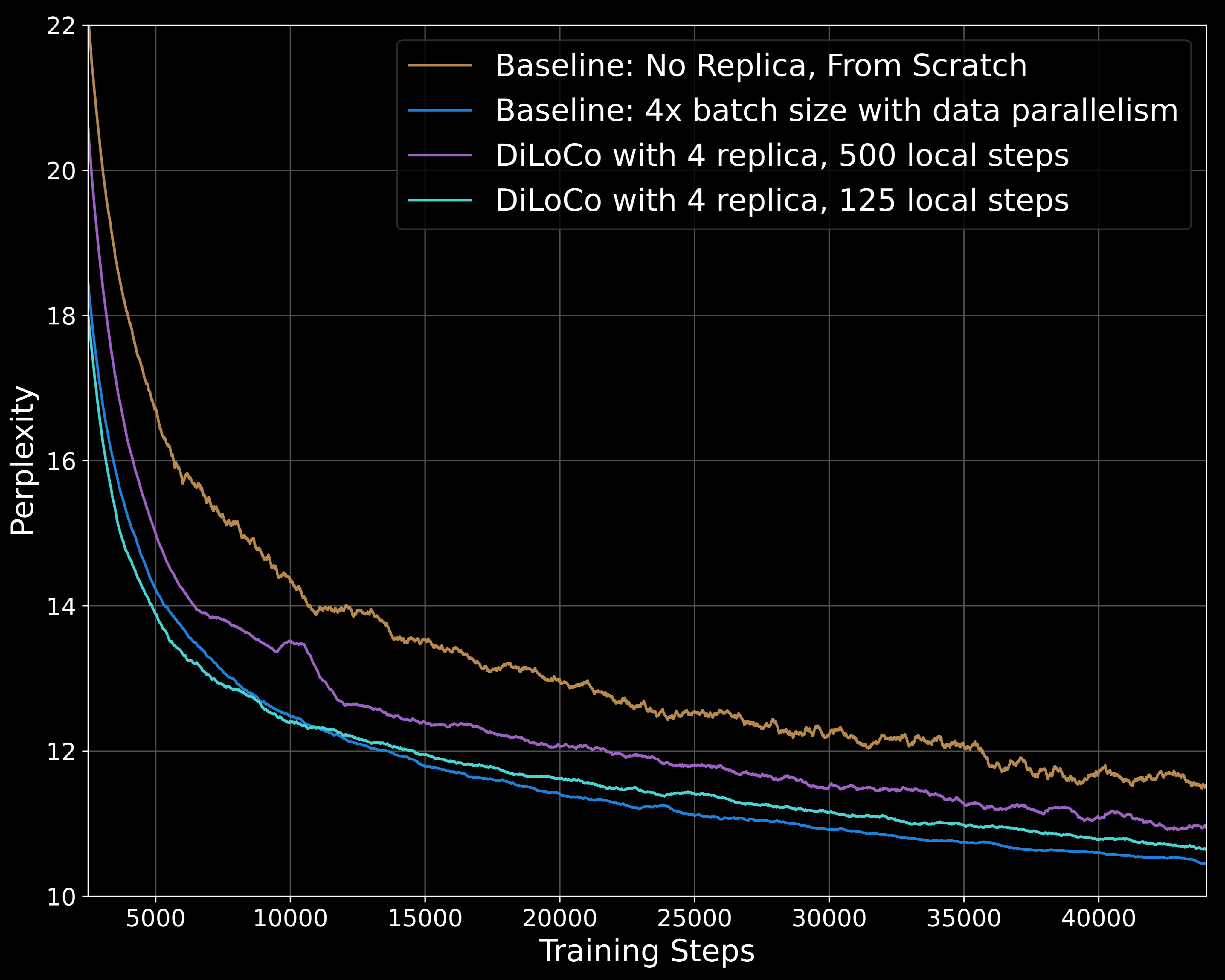
虽然我们证明了 DiLoCo 在十亿参数规模下工作,但我们认为还需要进一步的工作才能使其在更大的批量大小和增加的本地步骤中有效。
全球分布式训练设置
为了展示 OpenDiLoCo 在不同大洲进行分散训练的功能,我们使用了四个 DiLoCo 工作人员,每个工作人员有八个 H100 GPU,分别位于加拿大、芬兰和美国的两个不同州。图中显示了工作线程之间的网络带宽,在127到935 Mbit/s之间变化。我们用 500 个局部步骤训练了我们的 1.1B 参数模型,在 FP16 中梯度全部减少。由于本地步骤数量众多,四名工作人员独立运行了大约 67.5 分钟,然后进行梯度平均通信。对于外部优化器步骤,我们的实验显示,工作线程之间的平均全缩减时间为 300 秒。
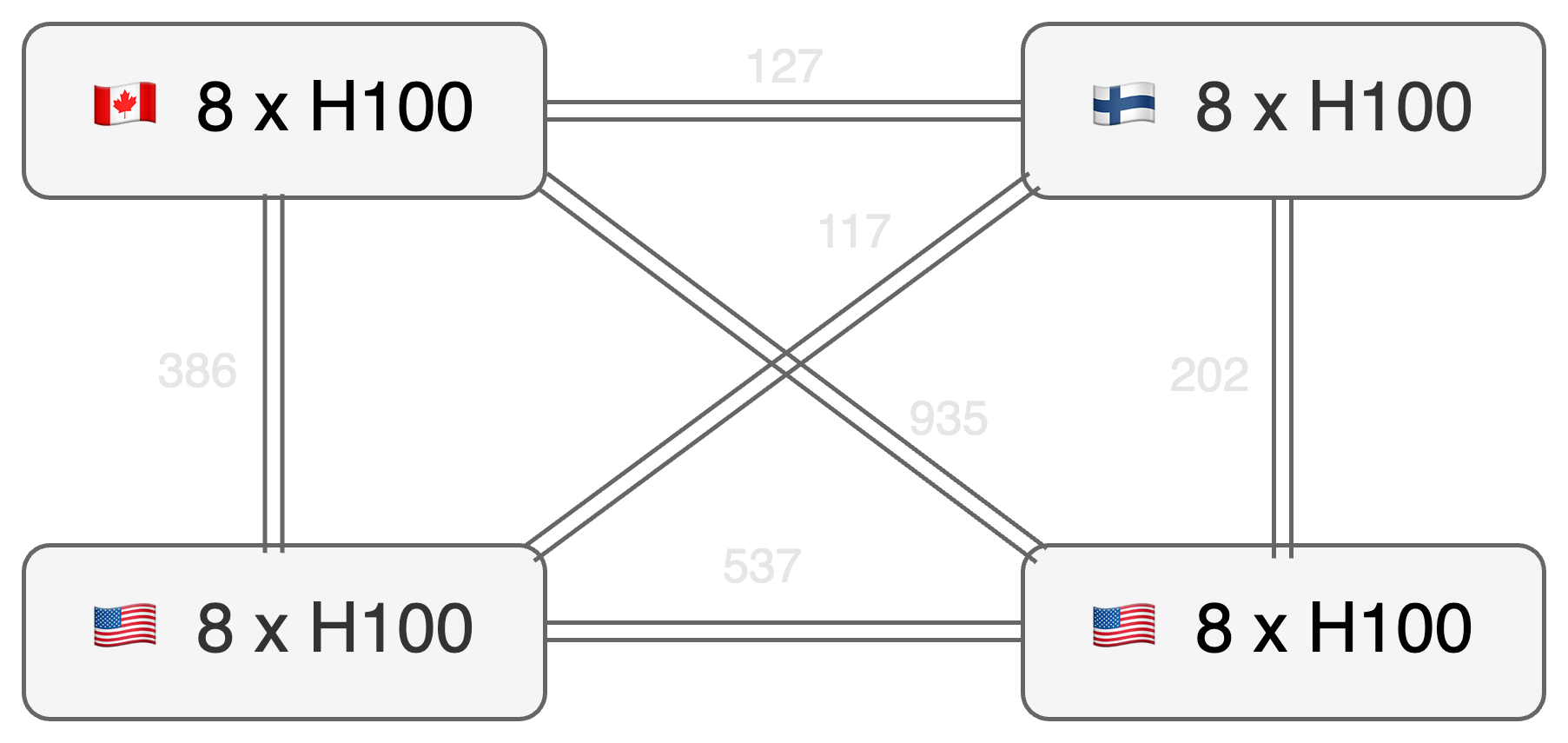
由于 DiLoCo 显著缩短了通信时间,因此 all-reduce 瓶颈仅占训练时间的 6.9%,对整体训练速度的影响最小。
在我们的场景中,最快的工作人员将花费额外的训练时间。在未来的工作中,我们将通过在异步环境中探索 DiLoCo 来解决这个问题。
运行 OpenDiLoCo
运行代码很简单。唯一的要求是可以访问至少两个 GPU,它们不必位于同一位置。设置环境后,使用以下命令创建初始 DHT 节点:
|
1 2 3 |
python ../hivemind_source/hivemind/hivemind_cli/run_dht.py --identity_path fixed_private_key.pem --host_maddrs /ip4/0.0.0.0/tcp/30001 |
在另一个终端中,您可以使用以下命令启动 DiLoCo worker,确保将 和 适当地设置:PEERNUM_DILOCO_WORKERSWORLD_RANK
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
export PEER=/ip4/192.168.100.20/tcp/30001/p2p/Qmbh7opLJxFCtY22XqwETuo6bnWqijs76YXz7D69MBWEuZ # change the IP above to your public IP if using across nodes connected via internet export NUM_DILOCO_WORKERS=4 export WORLD_RANK=0 torchrun --nproc_per_node=8 \\ train_fsdp.py \\ --per-device-train-batch-size 16 \\ --total-batch-size 2048 \\ --total-steps 88_000 \\ --project OpenDiLoCo \\ --lr 4e-4 \\ --model-name-or-path PrimeIntellect/llama-1b-fresh \\ --warmup-steps 1000 \\ --hv.averaging_timeout 1800 \\ --hv.skip_load_from_peers \\ --hv.local_steps 500 \\ --hv.initial-peers $PEER \\ --hv.galaxy-size $NUM_DILOCO_WORKERS \\ --hv.world-rank $WORLD_RANK \\ --checkpoint_interval 500 \\ --checkpoint-path 1b_diloco_ckpt |
您可以在 GitHub 存储库的 README 中找到有关运行 OpenDiLoCo 的更多信息。
在 PI 计算平台上运行 OpenDiLoCo
设置全局编排层以运行 DiLoCo 训练运行仍然非常具有挑战性。得益于我们预构建的 OpenDiLoCo docker 映像,我们的 PI 计算平台使这变得更加容易。该映像预装了所有依赖项,允许人们轻松生成 DiLoCo 工作线程。
在未来的工作中,我们很高兴在计算平台中构建一个集成的开源堆栈,为跨多个集群的编排、效率优化、处理节点故障、基础设施监控等提供流畅的解决方案。
结论和未来方向
我们成功再现了DiLoCo的主要实验结果,将该方法的参数大小缩放到原始工作的三倍,并演示了其在真实世界的分散训练环境中的应用。
对于未来的工作,我们的目标是将 DiLoCo 扩展到更多分布式工作线程的更大模型。一些有趣的方向包括可以提高稳定性和收敛速度的模型合并技术。此外,通过实现异步执行权重平均通信的方法,可以减少计算空闲时间,将它们与下一个外部优化步骤的计算交织在一起。
我们对这项技术的直接实际应用感到兴奋,并期待在不久的将来为我们总体规划的第三部分建立它:在语言、代理、代码和科学等高影响力领域协作训练和贡献开放 AI 模型,以实现 AI 模型的集体所有权。
加入我们,共建人工智能的开放未来
塑造人工智能未来的权力不应该集中在少数人手中,而应该向任何有能力做出贡献的人开放。我们诚邀您加入我们,共同构建一个更加分布式和有影响力的人工智能未来:
- 如果您雄心勃勃并希望实现这一目标,请申请我们的空缺职位。
- 就我们的 AI 模型计划和开源框架进行协作。
- 在最先进的 AI 模型中贡献、计算和赢得所有权。
我们的 OpenDiLoCo 工作也被 ICML 的 ES-FoMo 研讨会所接受。如果您要来维也纳,请联系我们!