微调 LLM
传统的微调(如下图所示)对于 LLM 来说是不可行的,因为这些模型有数十亿个参数,大小为数百 GB,而且不是每个人都可以访问这样的计算基础设施。

值得庆幸的是,今天,我们有许多微调 LLM 的最佳方法,下面描述了五种这样的流行技术:

我们在这里详细介绍了它们:
下面是一个简短的解释:
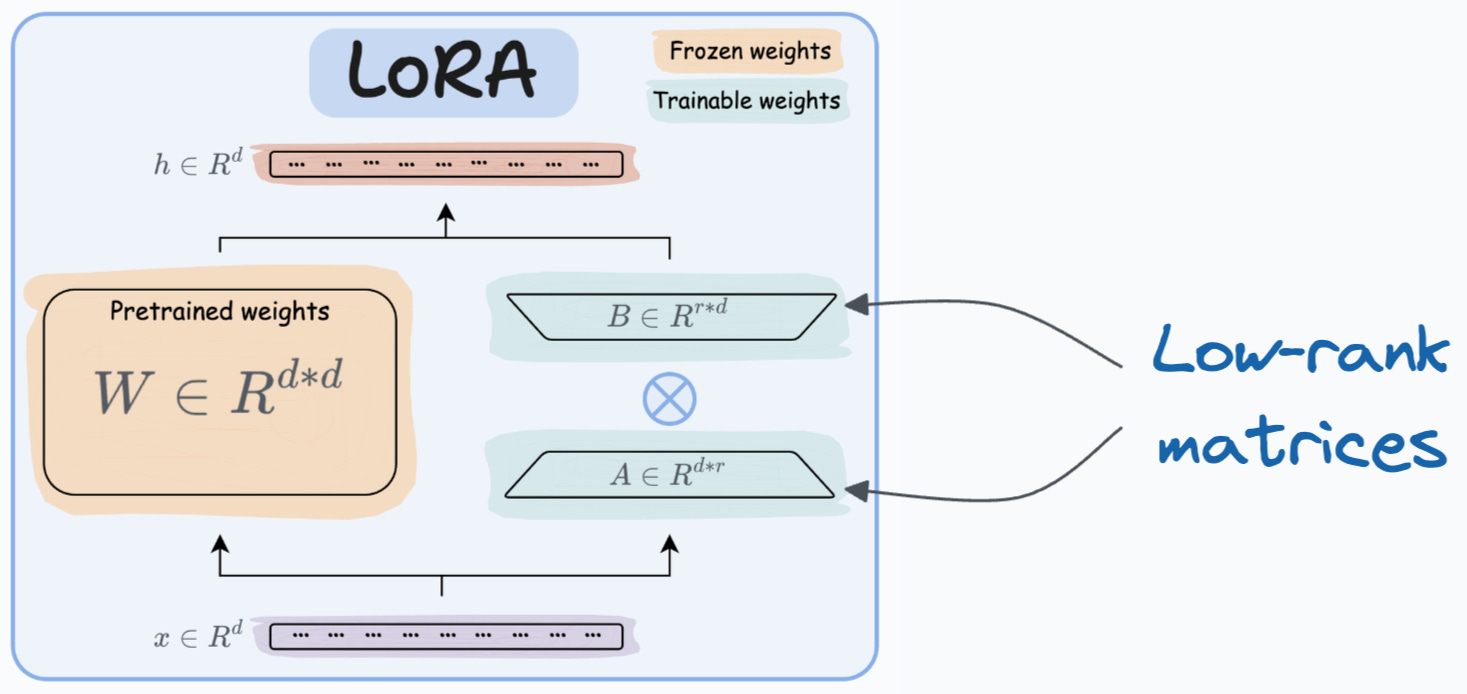
- LoRA:添加两个低秩矩阵 , 并添加包含可训练参数的权重矩阵
A和B。而不是微调W,调整这些低秩矩阵中的更新。
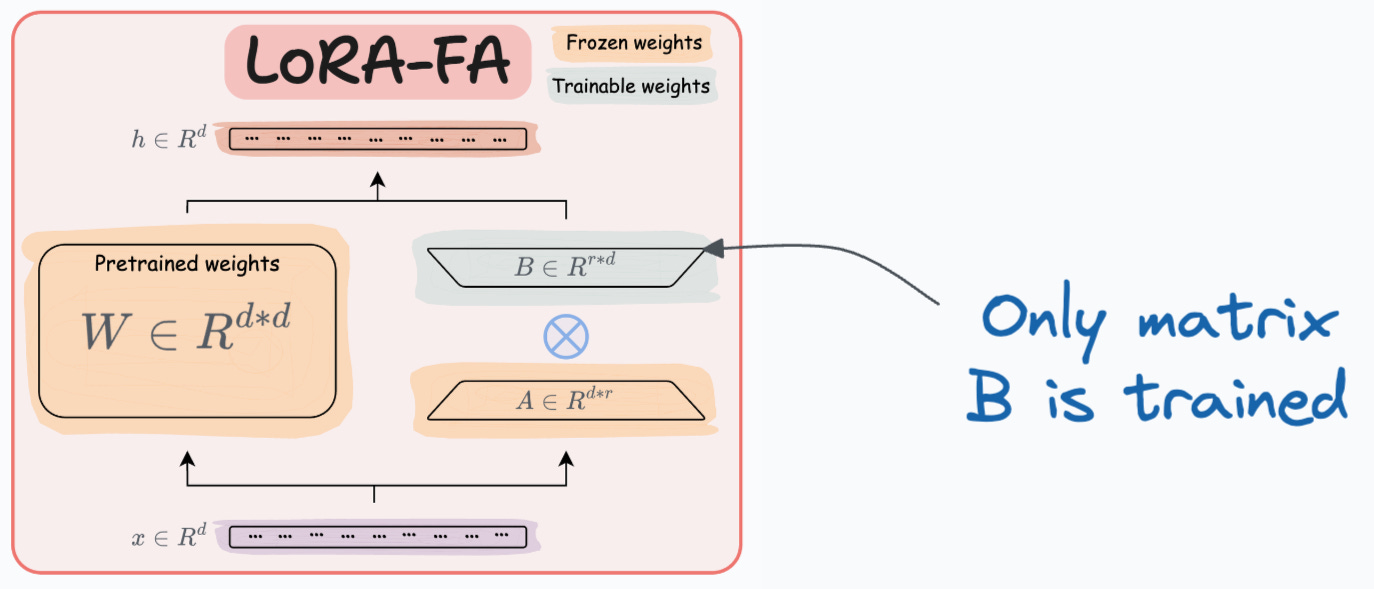
- LoRA-FA:虽然 LoRA 大大减少了可训练参数的总量,但它仍然需要大量的激活内存来更新低秩权重。LoRA-FA(FA 代表 Frozen-A)冻结矩阵
A并仅更新矩阵B。
- VeRA:在 LoRA 中,每一层都有一对不同的低秩矩阵
A和B,并且两个矩阵都经过训练。然而,在 VeRA 中,矩阵A和B是冻结的、随机的,并在所有模型层之间共享。VeRA 专注于学习小的、特定于层的缩放向量,表示为b和d,它们是此设置中唯一可训练的参数。

- Delta-LoRA:这里,除了训练低秩矩阵外,矩阵
W也进行了调整,但不是以传统方式进行调整。取而代之的是,低秩矩阵的乘积A与B两个连续训练步骤之间的差值(或增量)被添加到W:

- LoRA+:在 LoRA 中,矩阵
A和矩阵B都以相同的学习率进行更新。作者发现,为矩阵B设置更高的学习率 会导致更优化的收敛。

要更详细地了解确切的步骤、直觉和结果,请阅读以下文章:
也就是说,这些并不是唯一的 LLM 微调技术。以下视觉对象描绘了常用方法的时间线:

👉 交给你:有哪些方法可以降低微调 LLM 的计算复杂性?