这篇文章是关于你在讨论中LLM不断听到的各种量化技术。此处的目的是提供分步说明以及代码,您可以使用这些代码自行执行这些技术进行模型压缩。

1. Quantization 量化
量化是指将高精度数值转换为低精度数值。较低精度的实体可以存储在磁盘上的狭小空间中,从而减少内存需求。让我们从一个简单的量化示例开始,以明确概念。
1.1 量化的简单示例
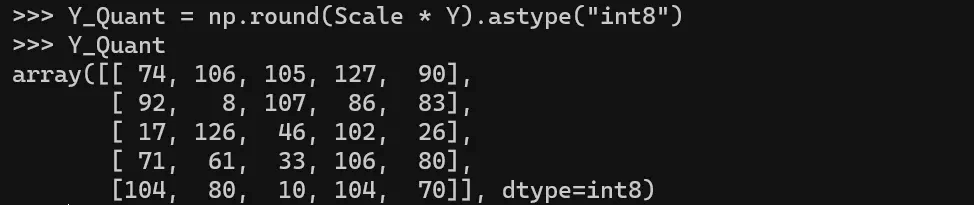
假设您有 FP16 格式的 25 个权重值,如下图所示。

- 旧 Range = 在 fp16 格式下是最大权重值减去最小权重值 = 0.932–0.0609 = 0.871
- 新 Range = 在 int8 格式下是 -128 to 127. 因此, Range = 127-(-128) = 255
- Scale = 新 Range 最大值 / 旧 Range 最大值 = 127 / 0.932 = 136.24724986904138
- Quantized Value(量化值) = Round(Scale * Original Value)
- 5. Dequantized Value(去量化值) = Quantized Value / Scale

6. Rounding Error(舍入误差) — 这里需要注意的重要一点是,当我们将 fp16 格式去量化时,我们注意到这些数字似乎并不完全相同。第一个元素 0.5415 变为 0.543。在大多数元素中都可以注意到相同的问题。这是量化结果的错误 – 去量化过程。
现在我们已经了解了量化的核心,让我们继续讨论量化的LLM类型。
2. GPTQ
- GPTQ 是训练后量化方法。这意味着一旦你进行了预训练LLM,你只需将模型参数转换为较低的精度。
- GPTQ 是 GPU 而不是 CPU 的首选。
- 下面列出了各种 GPTQ。
- Static Range(静态范围) GPTQ — 您可以以较低的精度转换权重和激活。
- Dynamic Range(动态范围) GPTQ — 您可以以较低的精度转换权重,并开发一个用于将激活转换为较低精度的函数。此函数最终将在推理过程中用于量化激活。
- Weight Quantization(权重量化) — 量化可以节省空间,因为它会降低权重的精度和/或模型的激活。在这里,在推理期间,输入仍然是 float32 格式,并且要使用输入进行权重计算,我们需要以与输入相同的精度返回权重。由于四舍五入问题,此过程会导致准确性下降。
2.1 Static Range Quantization 静态范围量化
- 如果你打算量化权重和激活,你需要一个样本校准数据集来做GPTQ。
- 校准数据集 — 此数据集可以从原始数据集中采样。例如,从原始预训练数据集中采样的 1000 个数据点充当整个数据集的代表性样本。
- 在校准数据集上进行推理 — 您将使用此校准数据集进行推理,以查找采样权重和相应激活的分布。该分布将作为量化的基础。
- 例如,特定层中的激活范围为 0.2 到 0.9,权重范围为 0.1 到 0.3。一旦你有了范围,即最小值-最大值,你就可以使用本文前面解释的数学方法对该层进行量化。
- 静态距离量化算法概述
- 我们在 GPTQ 算法中逐层量化神经网络。
- 我们将每层的权重指标划分为几组列。
- 这些列组以迭代方式进行处理。让我们通过一个例子来了解这一点。
- 如果我们将 GPTQ 的 group_size 参数设置为 128;权重指标分为一组,每组 128 列。
- 在包含 128 列的每个组中,对一列的数据进行量化;之后,该组中的其余权重将更新,以补偿量化引入的误差。
- 一次,处理一组列对应的数据;整个矩阵(其他组)上的其余列将更新以补偿误差。
- 这个完整的过程也称为“延迟批量更新”
- 现在让我们看一些代码。
2.2 GPTQ代码
- 这种量化需要 GPU。
- 起初,我尝试量化 7B 分片米斯特拉尔模型,但失败了。这是因为该模型在下载时首先加载到 CPU,而 T4 没有足够的 CPU RAM 来支持。
- 我最终选择了一个小尺寸的模型,可以容纳在 Google Collab 上的免费 T4 实例中。该模型是来自 HF repo 的 bigscience/bloom-3b。
|
1 |
pip install auto_gptq |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import torch from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig from transformers import TextGenerationPipeline from transformers import AutoTokenizer pretrained_model_name = "bigscience/bloom-3b" quantize_config = BaseQuantizeConfig(bits=4, group_size=128) # Tensors of bloom are of float16. Hence, torch_dtype=torch.float16. Do not leave torch_dtype as "auto" as this leads to a warning of implicit dtype conversion model = AutoGPTQForCausalLM.from_pretrained(pretrained_model_name, quantize_config, trust_remote_code=False, device_map="auto", torch_dtype=torch.float16) # changing device map to "cuda" does not have any impact on T4 GPU mem usage. tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name) # Calibration examples = [ tokenizer( "Automated machine learning is the process of automating the tasks of applying machine learning to real-world problems. AutoML potentially includes every stage from beginning with a raw dataset to building a machine learning model ready for deployment." ) ] # giving only 1 example here for testing. In an real world scenario, you might want to give 500-1000 samples. model.quantize(examples) quantized_model_dir = "bloom3b_q4b_gs128" model.save_quantized(quantized_model_dir) |
原文链接:https://medium.com/@siddharth.vij10/llm-quantization-gptq-qat-awq-gguf-ggml-ptq-2e172cd1b3b5