LoRA 代表低阶适应,是一种更有效地微调 LLMs 的流行技术。 LoRA 不调整深度神经网络的所有参数,而是专注于仅更新一小部分低秩矩阵.
从头开始编码来解释 LoRA 的工作原理,这是了解算法底层的绝佳练习.
1. 了解 LoRA
预训练的 LLMs 通常被称为基础模型,因为它们在各种任务中具有多功能性。然而,针对特定数据集或任务调整预训练的 LLM 通常很有用,我们可以通过微调来完成。
微调允许模型适应特定领域,而无需进行昂贵的预训练,但更新所有层的计算成本仍然很高,尤其是对于较大的模型。
LoRA 提供了比常规微调更有效的替代方案。正如《LoRA:大型语言模型的低秩适应》一文中更详细讨论的那样,LoRA 以低秩格式近似训练期间层的权重变化 ΔW。
例如,在常规微调中,我们将权重矩阵 W 的权重更新计算为 ΔW,而在 LoRA 中,我们通过两个较小矩阵 AB 的矩阵乘法来近似 ΔW,如下图所示。 (如果您熟悉 PCA 或 SVD,请将其视为将 ΔW 分解为 A 和 B。)
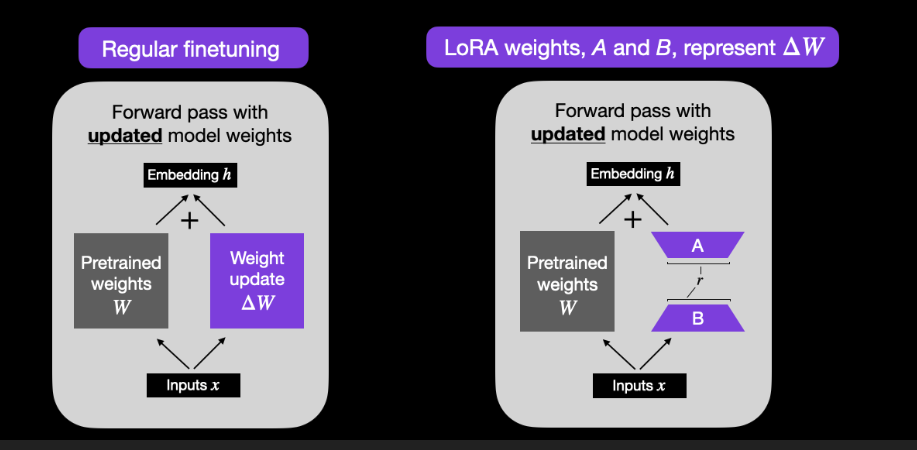
常规微调(左)和 LoRA(右)中前向传递过程中权重更新之间的比较。
请注意,上图中的 r 是一个超参数,我们可以用它来指定用于适应的低秩矩阵的秩。较小的 r 会导致更简单的低秩矩阵,从而导致在适应过程中需要学习的参数更少。这可以带来更快的训练并可能减少计算需求。然而,随着 r 的减小,低秩矩阵捕获特定任务信息的能力会降低。
举个具体的例子,假设给定层的权重矩阵W的大小为5,000×10,000(总共50M个参数)。如果我们选择秩r=8,我们初始化两个矩阵:5,000×8维矩阵B和8×10,000维矩阵A。加在一起,A和B只有80,000 + 40,000 = 120,000个参数,即400倍小于通过ΔW进行常规微调的50M参数。
在实践中,尝试不同的 r 值以找到适当的平衡以在新任务中实现所需的性能非常重要。
2. 从头开始编写 LoRA 代码
由于概念解释有时可能很抽象,因此现在让我们自己实现 LoRA,以更好地了解它的工作原理。在代码中,我们可以按如下方式实现 LoRA 层:
在上面的代码中, in_dimout_dim
我们之前讨论过,矩阵 A 和 B 的 rank 是一个超参数,用于控制LoRA引入的附加参数的复杂性和数量。
然而,看看上面的代码,我们添加了另一个超参数,即缩放因子 alphaalpha * (x @ A @ B)alpha 值越高,意味着对模型行为的调整越大,而值越低,变化越细微。
另一件需要注意的事情是,我们使用随机分布中的小值初始化了 AABABLoRALayer 不会影响原始权重,因为 AB=0 if B=0 。
请注意,LoRA 通常应用于神经网络的线性(前馈)层。例如,假设我们有一个简单的 PyTorch 模型或具有两个线性层的模块(例如,这可能是变压器块的前馈模块)。假设该模块的forward方法如下所示:
如果我们使用 LoRA,我们会将 LoRA 更新添加到这些线性层输出中,如下所示:
在代码中,当通过修改现有 PyTorch 模型来实现 LoRA 时,实现线性层的这种 LoRA 修改的一种简单方法是将每个线性层替换为 LinearWithLoRALinearLoRALayer
上述这些概念总结如下图
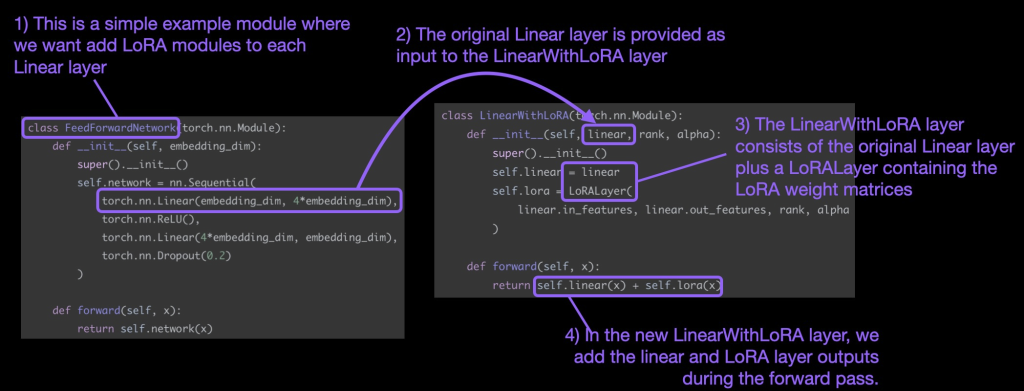
在实践中,要使用 LoRA 装备和微调模型,我们所要做的就是用新的 LinearWithLoRA 层替换其预训练的 Linear 层。我们将在下面的实践部分中通过将 LinearWithLoRA 层应用于预训练的语言模型来了解其工作原理。
3. 使用 LoRA 进行微调——一个实践示例
LoRA 是一种可以应用于各种类型神经网络的方法,而不仅仅是 GPT 或图像生成模型等生成模型。对于这个实践示例,我们将训练一个用于文本分类的小型 BERT 模型,因为分类准确性比生成的文本更容易评估。
特别是,我们将使用 Transformer 库中的预训练 DistilBERT(BERT 的较小版本)模型
由于我们只想训练新的 LoRA 权重,因此我们通过将所有可训练的 requires_gradFalse
接下来,让我们使用 print(model) 简要检查模型的结构:
根据下面的输出,我们可以看到该模型由 6 个包含线性层的 Transformer 层组成:
此外,该模型还有两个 Linear 输出层:
我们可以通过定义以下分配函数和循环来选择性地为这些 Linear 层启用 LoRA:
我们现在可以使用 print(model) 再次检查模型以检查其更新后的结构:
如上所示, Linear 层已成功替换为 LinearWithLoRA 层
如果我们使用上面显示的默认超参数选择来训练模型,则会在 IMDb 电影评论分类数据集上产生以下性能:
- Train acc: 92.15%
- Val acc: 89.98%
- Test acc: 89.44%
4. 与传统微调的比较
在上一节中,我们在 LoRA 默认设置下获得了 89.44% 的测试准确率。这与传统的微调相比如何?
让我们从训练 DistilBERT 模型开始,但在训练期间仅更新最后 2 层。我们可以通过首先冻结所有模型权重,然后解冻两个线性输出层来实现这一点:
仅训练最后两层后,所得分类性能如下:
- Train acc: 86.68%
- Val acc: 87.26%
- Test acc: 86.22%
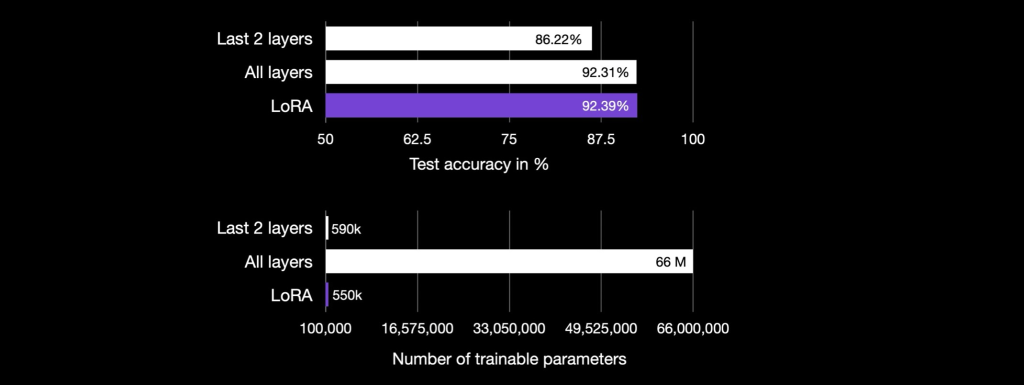
正如我们所看到的,LoRA 的测试准确率达到 89.44%,优于仅训练上面最后两层的情况。此外,上面的LoRA配置也更轻,因为它只需要训练147,456个参数。相比之下,对最后两层进行微调需要更新 592,130 个参数,这两个层很大。
现在,微调所有图层怎么样?
如果我们以传统方式微调 DistilBERT 模型的所有层,我们将获得以下结果:
- Train acc: 96.41%
- Val acc: 92.80%
- Test acc: 92.31%
因此,正如我们所看到的,微调所有层(涉及训练 66,955,010 个参数)比仅微调最后两层(592,130 个参数)和 LoRA 默认层(147,456 个参数)表现更好。
作为一个要点,到目前为止,LoRA 的性能比最后两层的传统微调要好,尽管它使用的参数少了 4 倍。微调所有层需要更新的参数比 LoRA 设置多 450 倍,但测试精度也提高了 2%。
然而,需要考虑的一个方面是,到目前为止我们仅使用 LoRA 默认设置。也许我们可以通过不同的 LoRA 超参数配置来弥补完全微调和 LoRA 微调之间的差距?我们将在下一节中回答这个问题。
5. 优化LoRA配置
请注意,这仅涉及将 LoRA 应用于关注层的查询和值权重矩阵。或者,我们也可以为其他层启用 LoRA。此外,我们可以通过修改等级( lora_r )来控制每个 LoRA 层中可训练参数的数量。
要尝试不同的超参数配置,您可以使用我们的紧凑型 03_finetune-lora.py script ,它接受超参数选择作为命令行参数:
运行代码
此外,您还可以切换其他超参数设置,例如:
提高 LoRA 性能的一种方法是手动调整这些超参数选择。但是,为了使超参数调整更加方便,您还可以使用 03_gridsearch.py script ,它在所有可用的 GPU 上运行以下超参数网格:
03_finetune-lora-script.pyresults.txtfile 中。运行完成后检查 results.txt
导致:
- Val acc: 92.96%
- Test acc: 92.39%
请注意,即使 LoRA 设置只有一小部分可训练参数(500k)与(66M),这些精度甚至略高于通过完全微调获得的精度。
为了应用 LoRA,我们将神经网络中现有的线性层替换为结合了原始线性层和 LoRALayer 的 LinearWithLoRA 层。
6. 结论
过从头开始编码来了解低秩适应 (LoRA)。通过微调 DistilBERT 模型进行分类,我们发现 LoRA 比仅微调模型的最后一层要有利(92.39% 的测试准确率 vs 86.22% 的测试准确率)。